RAG for code is not embeddings plus a vector store
A commit lands, an endpoint starts failing, and an agent is asked: why did this auth middleware change? If your rag for code setup is just embeddings plus a vector store, it will usually return something plausible and slightly wrong: nearby chunks about auth, maybe a decorator, maybe a test, maybe an unrelated middleware file with similar vocabulary. That is the failure mode. Code retrieval needs more than chunk-level similarity.
The common mental model is too thin because code is not prose. The meaning of a file lives in symbols, calls, imports, tests, history, and ownership. A vector store can tell you what sounds similar. It cannot tell you what changed, who is responsible, or which context is safe to trust.
The obvious code query is where embedding-only RAG breaks first
Ask a model, “where is auth enforced?” or “why did this endpoint start failing after the last commit?” and embedding-only retrieval tends to do the same thing every time: it finds semantically close text. That often means the right topic, wrong layer.
A middleware file, a route handler, and a test helper can all mention auth, token, and request. In embedding space they look adjacent. In the codebase, they are not interchangeable.
This is the first place rag for code fails: the query is about behavior, but the retriever is optimized for similarity. Similarity is a useful primitive. It is not relevance.
Tree-sitter exists for a reason. Syntax-aware parsing gives you file and symbol boundaries, not just text chunks. Tree-sitter’s own docs describe it as a parser for building syntax trees incrementally, which is exactly why it is useful for code intelligence: code meaning is attached to structure, not paragraphs. graph-aware MCP server
 SIMILARITY IS NOT RELEVANCE
SIMILARITY IS NOT RELEVANCE
The problem is not that embeddings are bad. It is that they answer the wrong first question.
Embeddings find similarity, not responsibility
Embeddings are good at clustering concepts. They are not good at assigning responsibility.
That distinction matters in code. Two files can be semantically close and operationally very different. Consider auth.py and auth_test.py. Both mention login, headers, tokens, and failure cases. In embedding space, they may be neighbors. But one is the source of truth for behavior, and the other is evidence about expected behavior. If you hand an agent the test file first, it may answer confidently from the wrong layer.
A symbol graph is the missing structure layer here. It tells you which function owns a behavior, which file defines it, which callers depend on it, and what sits upstream or downstream. That is a different retrieval problem than text similarity.
This is why “find the most similar chunks” is such an incomplete mental model for rag for code. Code is organized by symbols, dependencies, and execution paths. A retriever that cannot see those relationships is guessing from prose.
One subtle failure surprised us early: the most semantically similar chunk was often the least useful one because it was a wrapper, not the implementation. The wrapper talked about the implementation more clearly than the implementation talked about itself. The vector store was doing its job. The job was wrong.
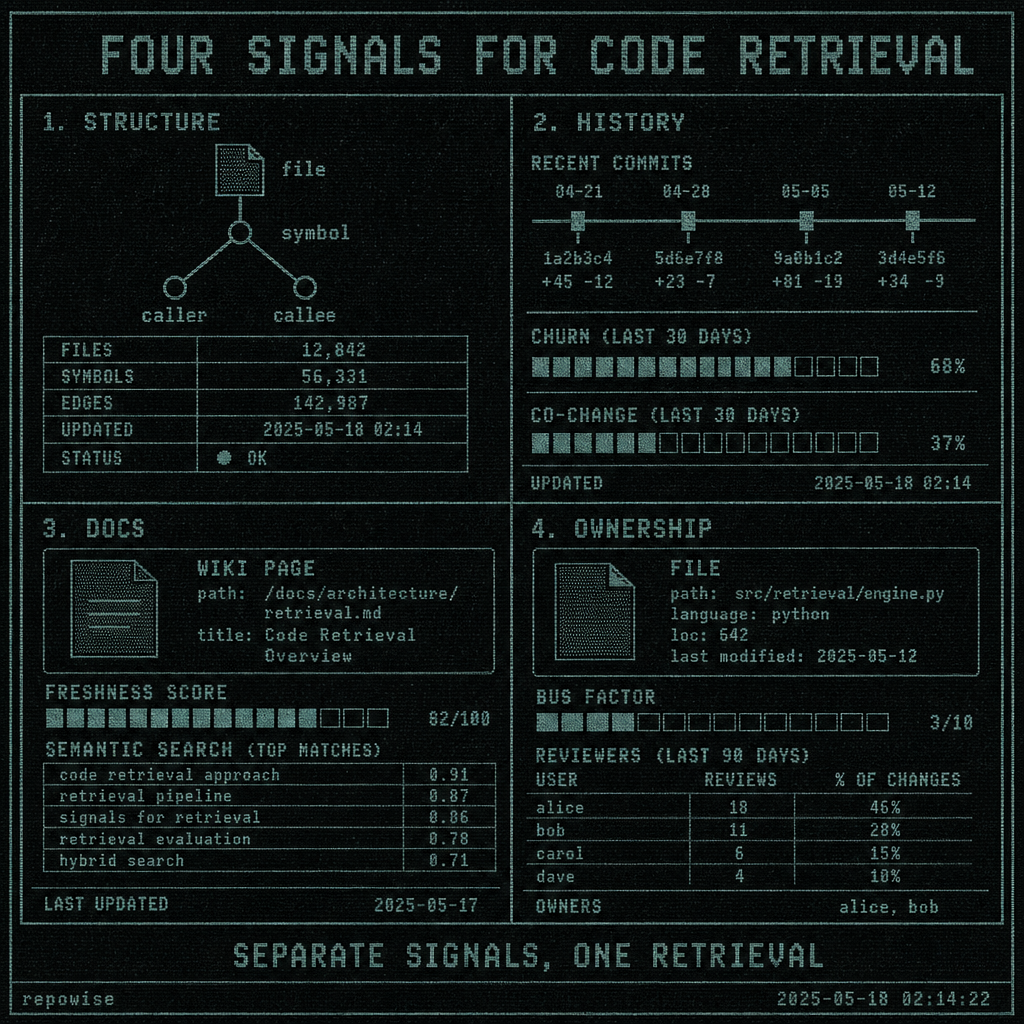
A code RAG system needs four signals, not one index
If you want rag for code to answer questions instead of just surfacing related text, you need four retrieval signals. They are not interchangeable.
| Signal | What it answers | What it is bad at |
|---|---|---|
| Structure | What symbol owns this behavior? What calls it? What depends on it? | Broad fuzzy recall |
| History | What changed recently? What churns together? What is stale? | Explaining intent by itself |
| Docs | What is the system supposed to do at a higher level? | Tracking exact runtime behavior |
| Ownership | Who is likely responsible? What is the bus factor? | Replacing code-level context |
Structure comes first. History comes next. Docs and ownership keep the model from hallucinating confidence.
A practical stack looks like this:
- Tree-sitter or a symbol graph for files, symbols, callers, callees.
- Git history for churn, co-change pairs, and freshness.
- Documentation intelligence for summaries and semantic search.
- Ownership signals for bus factor, reviewers, and file ownership percentages.
That is the difference between “retrieve similar text” and “retrieve the context needed to reason.”
task-shaped MCP tools are useful here because they force the retriever to answer a task, not dump a bag of chunks. That matters more than people expect.
Where tree-sitter, git history, and docs each earn their keep
Each layer earns its keep on a different class of question.
Tree-sitter is for boundaries. It gives you symbol extraction and dependency graph structure, which means the system can ask “what is this function?” instead of “what text mentions this function name?” If you are tracing a bug, that difference is everything.
Git history is for time. Relevance in code is temporal. Recent commits, churn, and co-change pairs often beat semantic similarity because they tell you where the work actually moved. A file that changed three times this week is more likely to matter than the file that merely talks about the same concept. Research on code churn and co-change has long shown that frequently changed files and coupled changes are useful predictors of maintenance hotspots and responsibility.
Documentation intelligence is for intent. A generated wiki with freshness scoring can answer “what is this subsystem supposed to do?” much faster than source code can. Source code is precise, but it is not written to be read as a design document. Docs are.
Decision records are for why. If you are asking “why does this exist?” or “why not the simpler version?”, source code is usually the wrong place to look. ADRs and inline decisions answer the question directly, and they age differently from implementation details. That distinction matters because stale intent is often worse than no intent.
 FOUR SIGNALS FOR CODE RETRIEVAL
FOUR SIGNALS FOR CODE RETRIEVAL
This is also where a lot of systems quietly overfit to embeddings. They use docs as a giant fallback because docs are easy to chunk. Then they wonder why the agent can describe the architecture but not change the bug.
Worked example: the same question through three retrievers
Take a concrete question: “Why did the auth middleware change in the last commit?”
Here is how three retrieval strategies behave.
| Retriever | Retrieved context | What it misses | Trust level |
|---|---|---|---|
| Embeddings-only | auth_test.py, a README section about JWT, a generic middleware utility | The actual changed symbol, callers, and whether the change is recent enough to matter | Low |
| Vector store + symbol graph | src/middleware/auth.py, enforce_auth(), its callers, adjacent tests | Whether this file was touched recently, whether another repo changed the contract, who owns it | Medium |
| Full stack: structure + history + docs + ownership | src/middleware/auth.py, last 3 commits touching it, co-change partner files, freshness-scored wiki entry, owner/reviewer signals | Very little; it still needs the model to reason, but the context is aligned with the question | High |
The best answer usually comes from fewer, better-targeted files rather than more chunks. That is the part teams resist, because more context feels safer. It usually is not.
A recent commit might show that enforce_auth() changed because a downstream API contract tightened, not because the auth logic itself was wrong. Embeddings alone will not infer that. A symbol graph plus history often will. If the wiki also says the middleware was refactored last week and the owner changed, the agent can stop guessing.
This is the real point of a graph-aware retrieval layer: not more text, but better selection before text ever reaches the model. graph-aware retrieval layer
When a smaller retriever beats a bigger index
There is a persistent temptation to fix weak retrieval by adding more embeddings, more chunks, and a larger vector store. That works until it doesn’t. Past a point, you are just making the haystack denser.
A smaller, graph-aware retriever wins when the question is about:
- ownership
- recent behavior
- call paths
- cross-file impact
- “what changed?”
- “what depends on this?”
Embeddings still help, but mostly as a ranking layer for broad recall. They are useful when you are searching docs, fuzzy names, or concepts that do not have a clean symbol handle yet. They are less useful when the question is about a specific path through the codebase.
A practical decision rule:
| Question type | Use embeddings? | Require structure/history first? |
|---|---|---|
| “Find docs about rate limiting” | Yes | No |
| “What file mentions this concept?” | Yes | Maybe |
| “Who owns this subsystem?” | No, not as the primary signal | Yes |
| “Why did this behavior change?” | Not first | Yes |
| “What call path reaches this endpoint?” | Not first | Yes |
That is the production rule: use embeddings for recall, but gate retrieval with structure and history before trusting the context. Ownership signals keep the agent from asking the wrong people. Docs and decisions keep it from inventing intent. A symbol graph keeps it from confusing similar text for the actual implementation.
If you want this to work in real agents, the retrieval layer has to be task-shaped, not blob-shaped. That is why we built around seven task-shaped MCP tools, not one generic search endpoint, and why the system can enrich Grep and Glob with graph context before the model sees them. token efficiency benchmark ownership and history signals
FAQ
Is RAG for code just embeddings and a vector store?
No. That model is useful for fuzzy recall, but it breaks on behavior, ownership, and recency. For code, retrieval has to combine embeddings with structure, git history, docs, and ownership signals or it will return plausible wrongness.
When should embeddings be used for code search?
Use embeddings for broad semantic search, docs lookup, and fuzzy names or concepts. They are a good ranking layer when you do not yet know the exact symbol or file, but they should not be the only signal for tracing behavior.
What does a symbol graph add to code retrieval?
A symbol graph adds the structure layer: files, symbols, callers, callees, imports, and dependencies. That lets the retriever answer “what owns this behavior?” instead of only “what text looks similar?”
How do git history and ownership improve code RAG?
Git history tells you what is recent, hot, and co-changing. Ownership tells you who is likely responsible and how risky a guess is. Together they reduce stale or irrelevant context and make retrieved answers safer to trust.
Why are docs and decision records separate from source code in retrieval?
Source code explains how something works right now. Docs explain the higher-level shape. Decision records explain why the design exists. Those are different questions, and code RAG is better when it can retrieve the right layer for each one.
