BLOG
Codebase intelligence,
explained
Guides on auto-generated documentation, MCP tools for AI agents, git intelligence, and how repowise compares to other tools.
Featured

Code Health: The Complete Guide (2026)
Code health is a defect-validated measure of how risky code is to change, scored from 25 deterministic biomarkers across three pillars. Reproduce it on your repo.
Giving AI Coding Agents Real Codebase Context
Codebase context for AI agents turns one index into 9 task-shaped MCP tools, cutting tokens 96% and stale guesses. See how structured context works — try repowise.
Latest
CLAUDE.md & AGENTS.md: The Complete Guide
What CLAUDE.md and AGENTS.md are, what to put in them, best practices, and how to keep them fresh automatically. Learn to give coding agents real repo context.
Code Health: The Complete Guide (2026)
Code health is a defect-validated measure of how risky code is to change, scored from 25 deterministic biomarkers across three pillars. Reproduce it on your repo.
Codebase Documentation That Stays Current
Living codebase documentation rebuilds on every commit, scores its own freshness, and feeds AI agents. Learn how it works and start with repowise free.
Git Intelligence: Hotspots, Ownership & Coupling Explained
Git intelligence reads your git history to surface hotspots, code ownership, bus factor, and change coupling. Learn how the signals work and where to start.
How to Prioritize Technical Debt (Impact-per-Effort)
Prioritize technical debt by impact-per-effort: rank refactoring targets, find dead code, and read coverage as risk. Build your ranked worklist today.
Giving AI Coding Agents Real Codebase Context
Codebase context for AI agents turns one index into 9 task-shaped MCP tools, cutting tokens 96% and stale guesses. See how structured context works — try repowise.
Does Code Health Predict Bugs? 21 Repos, 9 Languages, ROC AUC 0.74
A reproducible defect-prediction study: 21 repos, 9 languages, 2,770 labeled files, ROC AUC 0.74, and 2.3x more defects caught under a fixed review budget.
Onboard Engineers Faster on Any Codebase
Onboard engineers faster on any codebase with an auto-generated wiki and 9 MCP tools that recover the why behind legacy code. See the 30-day approach inside.
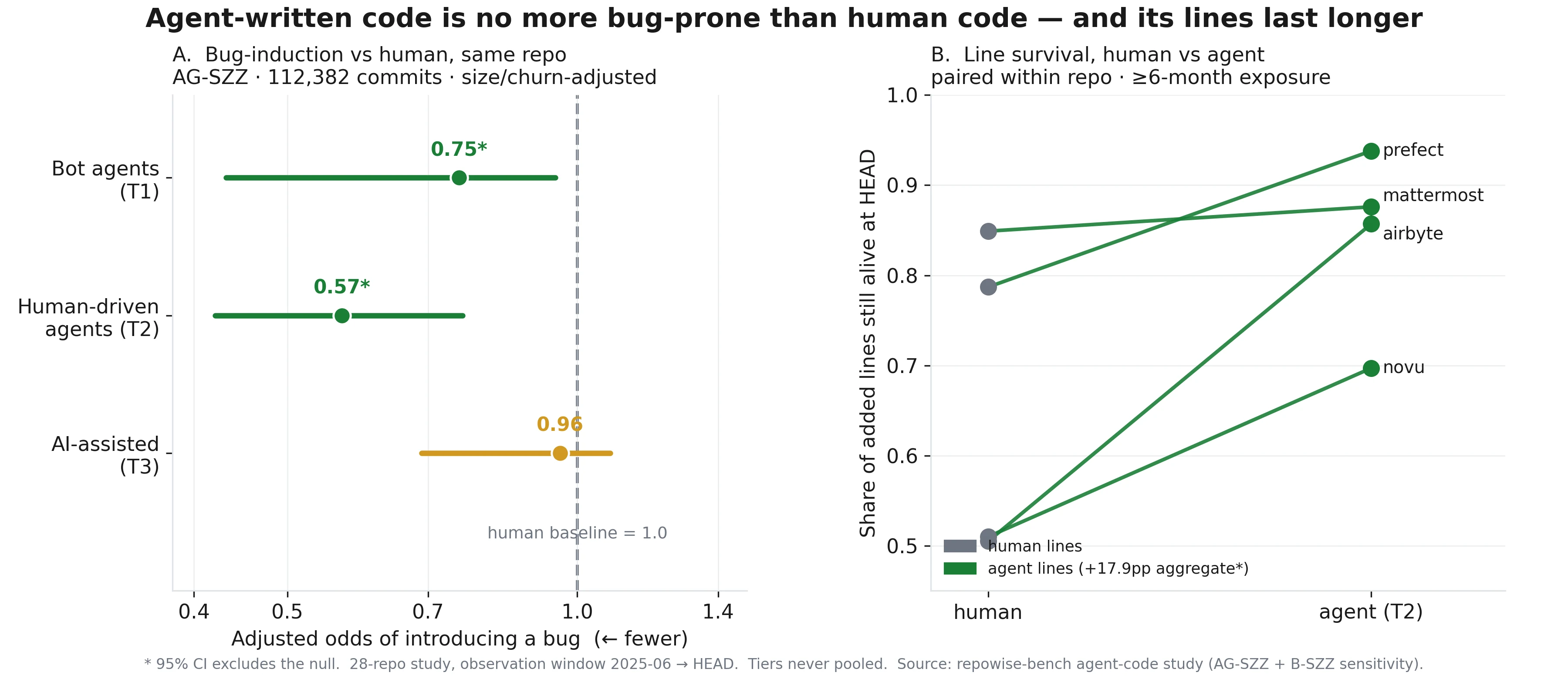
Is AI-written code buggier than human code? We blamed 112,000 commits to find out
We git-blamed 112,382 commits across 28 repos to test whether AI-agent code introduces more bugs than human code. After controlling for size, it doesn't, and its lines last longer.
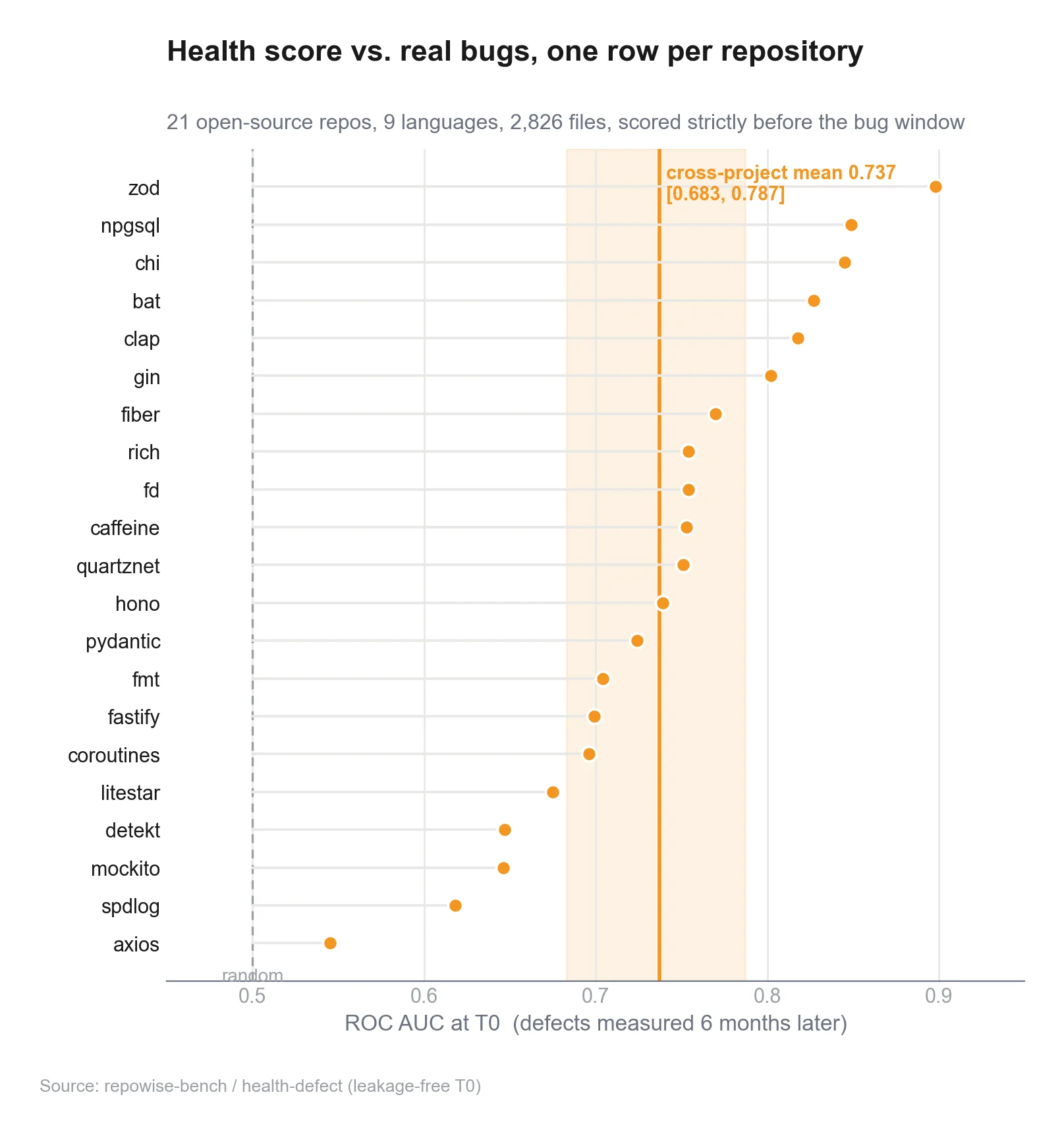
Does our code-health score actually predict bugs? A leakage-free benchmark
I scored 21 repos six months before their bugs landed to test whether a deterministic code-health score predicts defects. AUC 0.737, and the honest caveats.
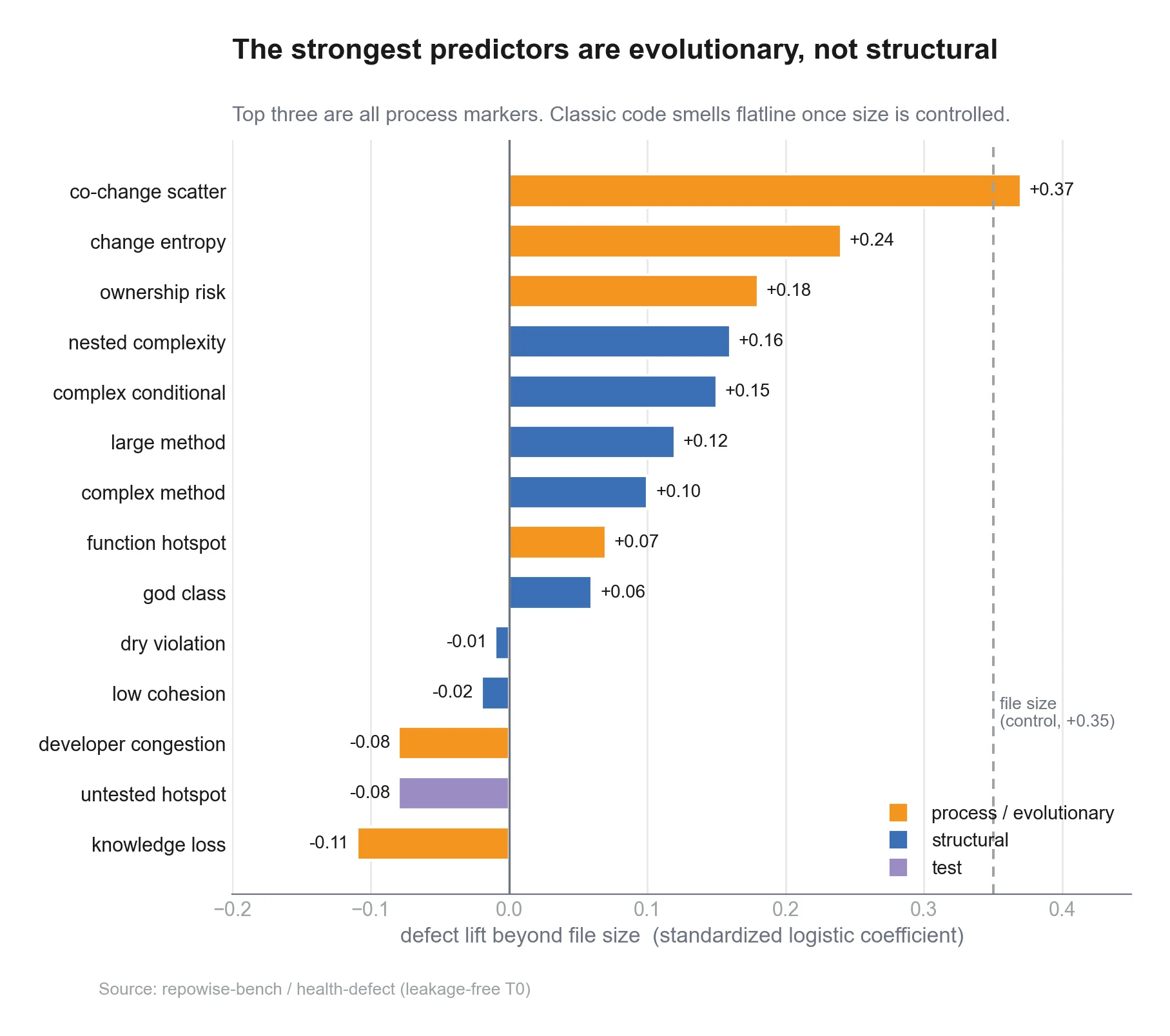
Process metrics beat structural metrics for predicting defects
Complexity and code smells are the metrics everyone reaches for. Across 25 markers and 21 repos, the strongest defect predictors were evolutionary, not structural. The numbers, with file size controlled.

Best AI Code Review Tools (LLM-Based and Deterministic)
Best AI code review tools fall into two camps: LLM-based reviewers that try to reason about intent, architecture, and change impact, and deterministic…
Try repowise on your repo
One command indexes your codebase and generates docs, graphs, and MCP tools.