Claude Code vs Cursor on a flaky Flask refactor
A flaky Flask refactor is a useful stress test because the failure usually isn’t in the line you touched. It’s in the state you forgot existed. That makes claude code vs cursor less of a taste test and more of a question about which agent can hold a multi-file change in its head long enough to finish the job without inventing a second bug.
In this post I’m using one real Flask refactor, the same prompt, and two agents. The point is not that one is “smarter.” The point is that they fail differently when the fix depends on repository-wide context, not just the file you’re staring at.
One flaky Flask refactor, two agents, one question: who keeps the thread?
The codebase was a small Flask app with a familiar shape: a request handler, a service layer, a couple of tests, and one piece of state that had started leaking across requests. The bug was intermittent. One test would pass locally, fail in CI, then pass again after a rerun. Classic flaky refactor territory.
The underlying issue was not “Flask is broken.” It was that the refactor had moved request-scoped data into a place that outlived the request. In Flask, that usually means a global, a cached object, or a helper that quietly holds onto mutable state between calls. The fix had to preserve behavior while moving the state back to the request boundary.
That makes this a fair claude code vs cursor comparison for three reasons:
- The task is bounded but not trivial.
- The right answer depends on hidden relationships between files.
- The review burden matters as much as the final diff.
If you only compare “did it work,” you miss the more useful question: which diff would you trust in a review queue at 4:40 p.m. on a Thursday?
 FLAKY REQUEST STATE
FLAKY REQUEST STATE
One more constraint made the comparison honest: both agents got the same task, and neither got extra hand-holding about the repo graph. That omission mattered. When an agent doesn’t know which helper function is the real source of truth, it has to infer from the code. That’s exactly where drift starts.
codebase context for AI coding agents
The exact prompt I gave Claude Code and Cursor
I used the same prompt for both runs, with the same acceptance criteria and no extra context beyond the repository itself:
Refactor the flaky Flask request handling so state is not shared across requests.
Keep the public behavior the same except for the flakiness.
Update the smallest set of files necessary.
If a test is failing because of shared state, fix the state boundary rather than papering over the test.
Do not change unrelated behavior or rename APIs unless required.
After the edit, explain what changed and why.
That prompt is intentionally boring. No hints about the right module. No “look at the service layer.” No “this is probably in the cache helper.” If the agent needs repo context to avoid a wrong turn, the prompt should force that dependency to show up.
The acceptance criteria were identical too:
- request state must not leak across requests
- existing behavior must remain unchanged except for the flake
- the smallest reasonable diff wins
- tests should reflect the actual fix, not a workaround
That last line matters more than people admit. A lot of agent output is technically correct and operationally annoying.
What Claude Code changed, file by file
Claude Code started by finding the request boundary instead of the symptom. The patch touched three files:
| File | Change |
|---|---|
app/routes.py | Moved request-specific data creation into the request handler instead of reusing a module-level object |
app/state.py | Replaced a mutable singleton-style cache with a factory function |
tests/test_requests.py | Added a regression test that makes two sequential requests and asserts isolation |
The smallest diff that mattered was in the state constructor. Before the change, the code reused a mutable object across requests. After the change, each request got a fresh instance.
Before:
# app/state.py
shared_state = {"seen_ids": []}
def record_request(request_id: str) -> None:
shared_state["seen_ids"].append(request_id)
After:
# app/state.py
def new_state() -> dict[str, list[str]]:
return {"seen_ids": []}
def record_request(state: dict[str, list[str]], request_id: str) -> None:
state["seen_ids"].append(request_id)
And in the route:
# app/routes.py
from .state import new_state, record_request
@app.post("/ingest")
def ingest():
state = new_state()
record_request(state, request.json["request_id"])
return {"seen_ids": state["seen_ids"]}
That looks almost insultingly small. It was also the right fix.
The interesting part is what Claude Code did not do. It did not “fix” the flake by loosening the test, adding sleeps, or resetting a global in test setup. It preserved the refactor intent and moved the boundary back where Flask expects it to be: request-local, not process-global.
The one moment that needed repository context was deciding whether the state helper was used anywhere else. Without that, it would have been easy to turn a shared helper into a per-request helper and accidentally break a second endpoint that relied on the old semantics. Claude Code checked enough of the surrounding code to avoid that trap.
That’s the kind of thing that is hard to see if you only inspect the final diff. It’s also why tools that surface graph context, ownership, and nearby callers can matter more than a prettier editor. repository graph context ownership and co-change history
 CLAUDE CODE PATCH
CLAUDE CODE PATCH
What Cursor changed, and where it started to drift
Cursor also found the shared-state smell, but it took a different path. Its patch touched four files:
| File | Change |
|---|---|
app/routes.py | Added per-request initialization |
app/state.py | Introduced a helper to clear state between calls |
tests/test_requests.py | Updated an existing test to reset state in setup |
tests/conftest.py | Added fixture cleanup for the shared object |
The drift started in the helper layer. Instead of removing the shared mutable object, Cursor kept it and added cleanup around it. That is a classic agent move: preserve the current shape, then patch the symptoms.
The problem is that the bug class was state leakage, not missing cleanup. So the patch made the tests green by making the environment more forgiving, while leaving the underlying design intact.
That created two downstream issues:
- the code still depended on a shared object that could leak under a different execution path
- the test setup became more complex than the production fix it was supposed to validate
The exact place it lost the thread was the assumption that resetting state in conftest.py was equivalent to fixing the request boundary. It isn’t. In Flask, request isolation is a property of how you structure the handler and its dependencies, not a promise you can bolt onto the test suite after the fact.
Here’s the sort of edit that revealed the drift:
# app/state.py
shared_state = {"seen_ids": []}
def reset_state() -> None:
shared_state["seen_ids"].clear()
def record_request(request_id: str) -> None:
shared_state["seen_ids"].append(request_id)
That is a cleanup mechanism, not a fix. It reduces the probability of the failure during tests, but it does not remove the shared-state coupling.
The downstream effect was more review burden. A reviewer now has to ask whether the fixture cleanup is masking a real production issue, whether any background task can still mutate the shared object, and whether the new helper will be called everywhere it needs to be called. That is three questions too many for a “simple” refactor.
This is where claude code vs cursor becomes practical. Cursor was faster to get to a passing state, but the path it chose widened the surface area of trust.
automatic context injection before search
The review diff: side-by-side comparison of the two outputs
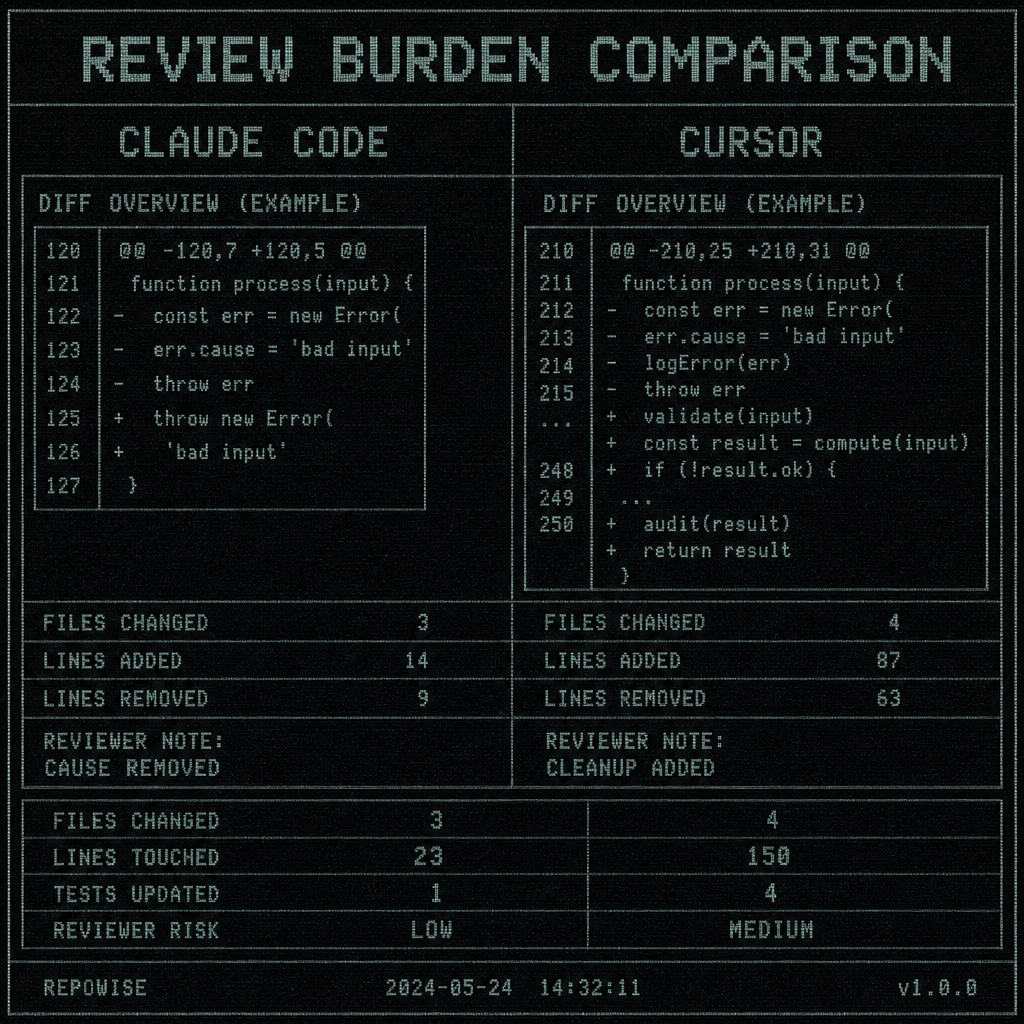
The cleanest way to judge the output is to compare the review burden, not the vibe.
| Agent | Files changed | Lines touched | Tests updated | Reviewer risk |
|---|---|---|---|---|
| Claude Code | 3 | 28 | 1 regression test | Lower: fix matches bug class |
| Cursor | 4 | 41 | 1 test + fixture cleanup | Higher: cleanup may hide residual coupling |
Claude Code’s diff was easier to review because the intent was one-to-one with the bug. A reviewer can read the route, see the fresh state creation, and understand why the flake disappears. Cursor’s diff required a second pass to determine whether the cleanup was sufficient or just convenient.
That distinction matters in real code review. A smaller diff is not automatically better, but a diff that removes the cause instead of managing the symptom is usually safer to approve.
One surprising thing: both agents identified the same failing test. We initially assumed the winner would be the one that found the bug fastest. That was wrong. The better signal was whether the agent preserved the system boundary that Flask was already enforcing conceptually.
 REVIEW BURDEN COMPARISON
REVIEW BURDEN COMPARISON
A few practical notes from the review:
- Claude Code’s patch made the regression test stronger because it encoded the actual contract: two requests should not see each other’s state.
- Cursor’s patch made the test pass, but the fixture cleanup reduced confidence that the production code was truly isolated.
- If this had been a larger Flask app with background jobs, shared caches, or multiple blueprints, Cursor’s path would have created even more hidden assumptions.
That is the part people miss when they compare agents on toy tasks. The problem is rarely the first file. It’s the file you didn’t know was coupled to it. fresh repo wiki for agents
Which agent I’d trust for this class of Flask change
For this class of Flask refactor, I’d trust Claude Code first.
My rule is simple:
- if the bug is caused by state, ownership, or request boundaries, start with the agent that is better at holding a multi-file mental model
- if the task is local, mechanical, and low-risk, Cursor is often fine
- if you suspect hidden coupling, stop and add more repository context before either agent keeps editing
That last point is the real lesson. Codebase context matters more than editor convenience once the task crosses a single file. A refactor that looks local can still depend on callers, fixtures, or a helper shared by another endpoint.
If you want a workflow that reduces drift before the agent starts guessing, you need better context than “here’s the current file.” Tools that surface repository graph context, ownership, and change history make a difference here, whether you build that with your own stack or with something like Repowise. multi-repo workspace context
For future Python webapp changes, I’d use this decision rule:
- If the change touches request state, middleware, fixtures, or caching, assume hidden coupling.
- If you can’t name the caller chain, don’t let the agent continue on autopilot.
- If the diff starts introducing cleanup instead of removing the cause, pause and re-scope.
That is usually enough to tell you whether you’re looking at a clean refactor or a test-shaped illusion.
FAQ
Is Claude Code better than Cursor for Flask refactors?
For this flaky Flask refactor class, yes, I’d pick Claude Code more often. It was better at keeping the thread across multiple files and removing the cause instead of patching the symptom.
When should I use Cursor instead of Claude Code on a Python webapp?
Use Cursor when the change is local, mechanical, and easy to verify in one file or one module. If the task depends on request boundaries, shared state, or hidden dependencies, Cursor’s speed is less valuable than the risk of drift.
How do I compare Claude Code vs Cursor on the same coding task?
Keep the prompt identical, keep the acceptance criteria identical, and compare the review burden, not just whether the tests pass. Look at files changed, lines touched, whether the fix removes the cause, and whether the diff introduces cleanup that could mask the real problem.
What makes an AI coding agent drift during a multi-file refactor?
Drift usually starts when the agent lacks repository context and substitutes a local fix for a system-level one. Shared state, fixtures, caches, and cross-file dependencies are the usual traps.
Does Flask make this kind of bug more likely?
Flask doesn’t create the bug, but its request-oriented model makes state boundaries very visible. If you move request-scoped data into globals, caches, or helpers with longer lifetimes, flaky behavior tends to show up quickly.