Codebase RAG Breaks on Git History, Not Embeddings
A lot of codebase RAG systems are good at the first lookup and bad at the second question. That is the real codebase rag landscape: not “can it find the file,” but “can it explain why the file exists, who owns it, and what changed around it.”
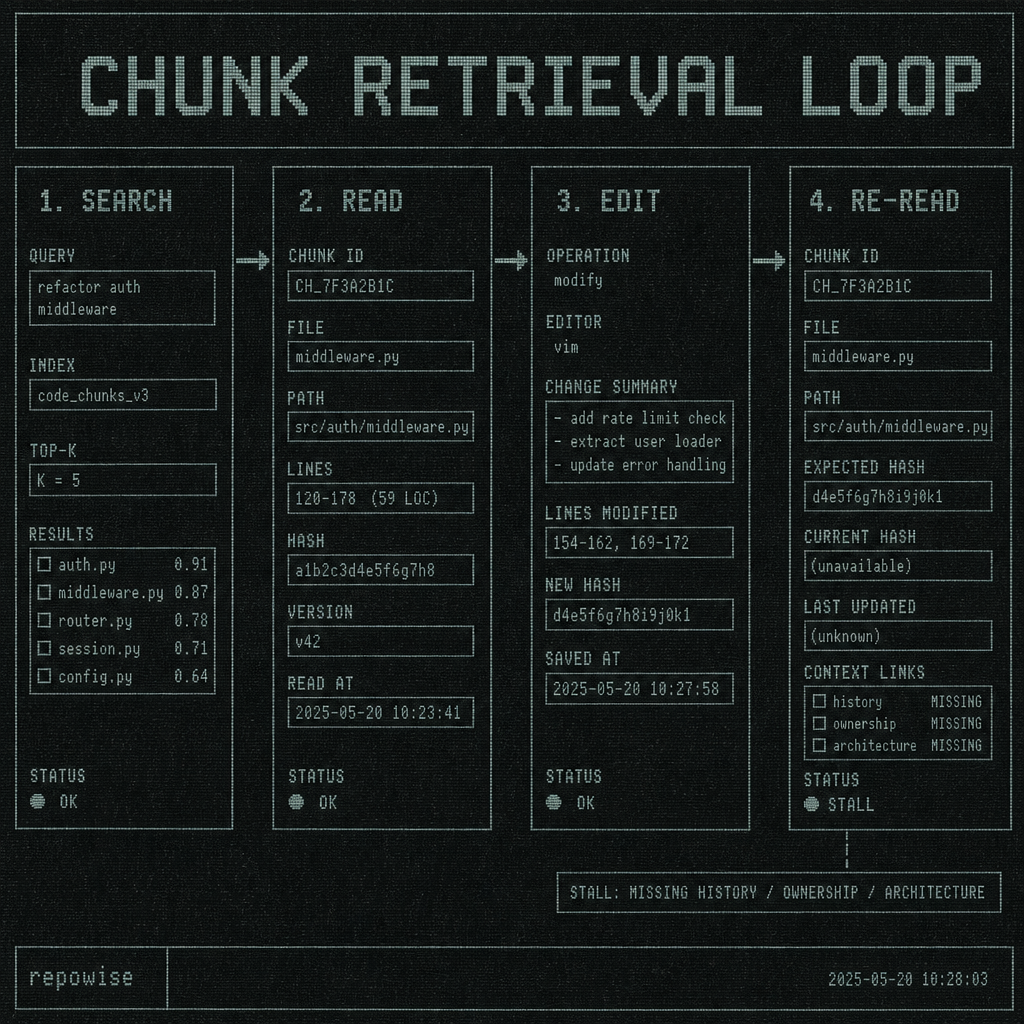
The failure mode is subtle because chunk retrieval looks successful. The model gets a snippet, cites a line, and sounds confident. Then the agent has to edit something adjacent, re-reads the same files, misses the surrounding change, and stalls. The system retrieved text, but it did not preserve the structure that makes a repository intelligible.
Chunk retrieval works for the first question, then falls apart on the second
The anti-chunking argument is simple: snippet retrieval is enough for a single lookup, but not for commit understanding or multi-step edits. A file chunk can tell you what a function does. It cannot tell you why the function was introduced, what it displaced, which subsystem it affects, or which reviewer will object if you touch it.
That gap shows up in a familiar agent loop:
- search for a symbol
- read the file
- edit the file
- re-read nearby files
- stall because the agent still doesn’t know whether the change belongs in this module or a neighbor
The first pass feels productive. The second pass reveals the missing layer. If the retrieval stack only returns chunks, the model keeps rediscovering local context that should have been indexed once.
 CHUNK RETRIEVAL LOOP
CHUNK RETRIEVAL LOOP
This is why the codebase RAG landscape is splitting. Search is still useful. It is just not sufficient for agent workflows that need to understand change over time.
A better before/after comparison looks like this:
| Step | Naive chunk RAG | Structure-aware retrieval |
|---|---|---|
| Find the relevant code | Returns the changed file and a few nearby chunks | Returns the file plus related symbols, callers, callees, and community context |
| Explain the change | Summarizes the diff hunk | Explains the commit in terms of prior history and architectural intent |
| Decide what to edit next | Re-reads adjacent files blindly | Surfaces owner, co-change partners, and blast radius |
| Avoid repeated work | Often re-searches the same symbols | Reuses indexed context and keeps the answer fresh after commits |
That last row matters more than it sounds. A system that cannot maintain context after the first answer is not a knowledge system; it is a nicer grep.
Git history is the retrieval layer most systems leave out
Git history is not optional metadata. It is the evidence trail for intent, regressions, hotspots, and reviewer patterns. If you flatten history into a few retrieved chunks, you lose the sequence of change, and sequence is usually the point.
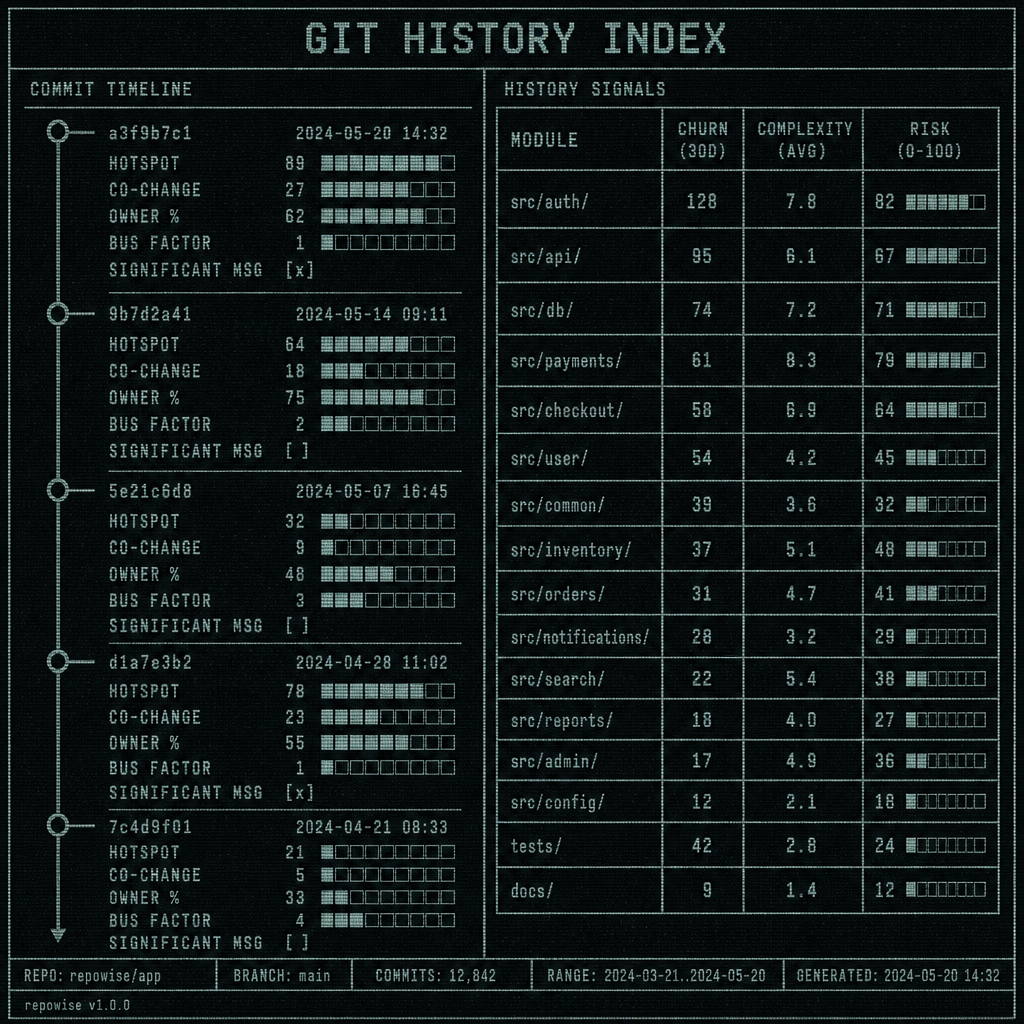
A codebase can look stable in a snapshot and still be in active churn under the surface. The interesting signals are rarely in the current file alone. They live in the commit graph: what changed together, what changed repeatedly, what got touched by many hands, and what was left alone because only one person knew the subsystem well enough to touch it.
The useful indexes here are not exotic:
- hotspots: churn × complexity
- co-change pairs
- ownership %
- bus factor
- significant commit messages
That is the difference between “this file mentions auth” and “this auth module has been rewritten six times, usually with the same payment code, and only two people have touched it in the last year.”
One practical detail: the history depth should be configurable. A default of 500 commits is a starting point, not a promise. Some repos need less. Some need the full log. The point is that git history needs to be a tunable retrieval layer, not an afterthought bolted onto search.
 GIT HISTORY INDEX
GIT HISTORY INDEX
This is also where a lot of “RAG for code” products quietly stop. They can tell you what text matched. They cannot tell you why the repository evolved the way it did. For agent workflows, that distinction is fatal.
Ownership and architecture need their own indexes, not just embeddings
Ownership and architecture are different retrieval problems.
Ownership asks: who actually changes this subsystem, who reviews it, who gets paged when it breaks, and what is the blast radius if we touch it? Authorship is a weak proxy. The person who wrote the file three quarters ago is often not the person who maintains it now.
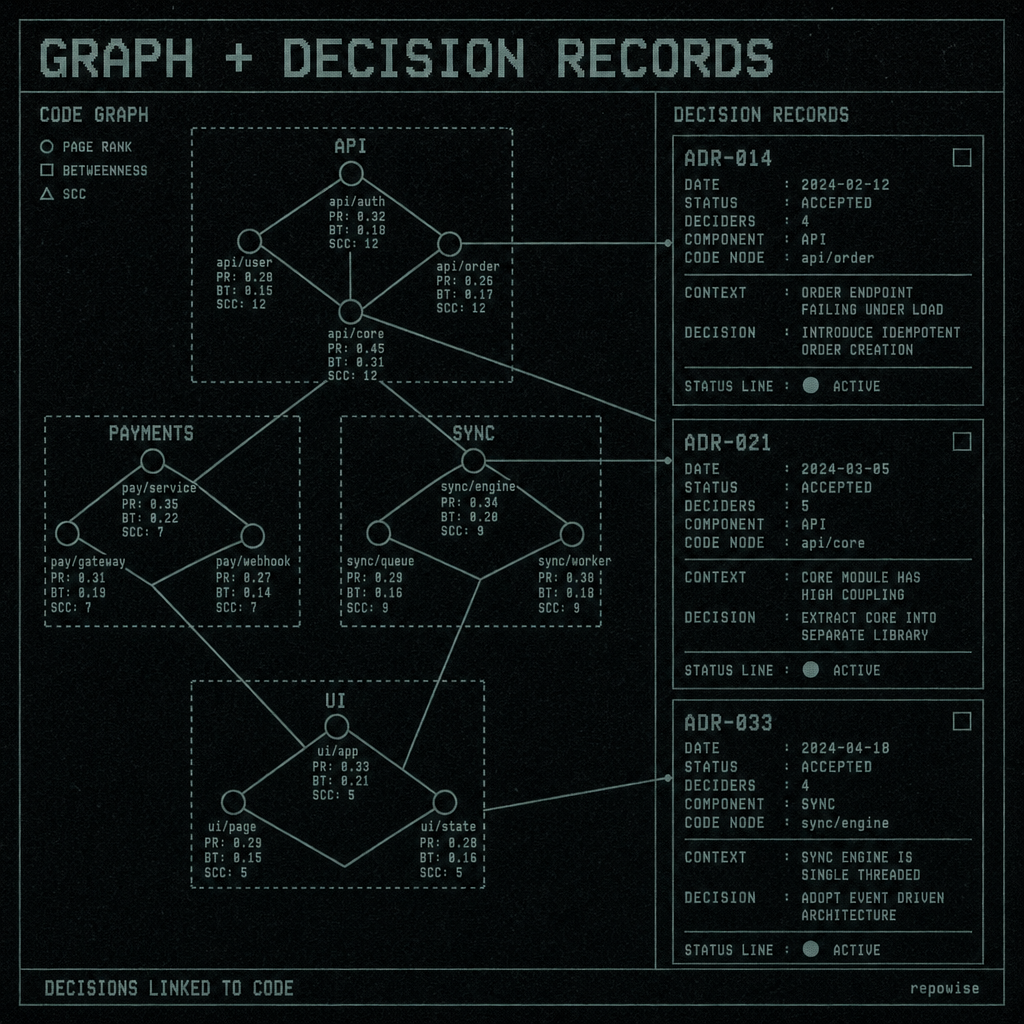
Architecture asks: where are the entry points, how do dependencies flow, which modules form communities, and what decisions explain the shape of the system? A semantic embedding can surface text that sounds related. It cannot, by itself, reconstruct the graph.
That is why a useful system needs a tree-sitter file and symbol graph, communities, PageRank, betweenness, SCC, and execution-flow tracing from entry points. Those are not ornamental metrics. They are the difference between “this file is mentioned in docs” and “this file sits on a high-betweenness path between the API layer and the storage layer.”
Architectural decision records matter for the same reason. A decision without a link to the graph is just a note. A decision linked to graph nodes becomes queryable context. You can ask why a module was split, what tradeoff was accepted, and whether the decision is now stale.
This is the part many systems get wrong initially. I used to assume that enough retrieval plus a good model would recover ownership from text. It mostly doesn’t. What surprised me is how often the model confidently invents a plausible maintainer from recent mentions, even when the real owner is visible only in change patterns and review history.
 GRAPH + DECISION RECORDS
GRAPH + DECISION RECORDS
If you want a concrete implementation pattern here, decision intelligence is the right mental model: decisions are not a separate wiki page, they are a queryable layer attached to code.
How DeepWiki, Sourcegraph, and code graphs split the problem
The codebase rag landscape is not one market. It is three partially overlapping categories pretending to be one.
Search-first systems, such as Sourcegraph, are very good at code search and code intelligence. They help you find symbols, jump through references, and answer “where is this used?” quickly. What they miss is usually not search quality; it is the broader repository memory needed for commit understanding and ownership questions.
Wiki-first systems, such as DeepWiki, are strong when the problem is “summarize this repo in human language.” They preserve the shape of the codebase as documentation. What they can flatten is the underlying dependency graph and the change history that keeps docs honest.
Graph-first systems keep the relationships explicit. They are strongest when the question is about architecture, hotspots, blast radius, or how a change propagates. What they can miss is readability. A graph without a narrative can be accurate and still annoying to use.
That split is useful because it clarifies what to ask a vendor. If the product only returns snippets, it is a search system. If it returns generated docs, it is a documentation system. If it can answer why a module exists, who owns it, and what depends on it, then it is doing repository intelligence.
A good workflow usually blends layers rather than worshiping one. graph-aware MCP server is one way to expose that blend to agents without forcing the model to assemble everything from raw text each time.
A worked example: what a vendor should return for a commit-understanding query
A vendor call gets much easier if you ask one concrete question: “Why did this commit change this module?”
The wrong answer is a diff summary. The right answer includes history, ownership, architecture, and related symbols.
| Field | Naive chunk RAG answer | Structure-aware answer |
|---|---|---|
| Changed symbols | Returns the edited function names | Returns the edited symbols plus callers, callees, and nearby modules |
| History | Mentions the current diff only | Summarizes recent churn, significant commits, and co-change pairs |
| Ownership | Omits it or guesses from authorship | Shows ownership %, active reviewers, and likely maintainer |
| Architecture | Uses local text to infer purpose | Explains the module’s role in the graph and its entry points |
| Reason for change | “Refactor for clarity” | “Moved validation earlier because this path sits on the API-to-storage boundary; ADR-021 changed the flow after a regression” |
| Next action | “Inspect surrounding files” | “Check dependent modules X and Y; owner Z should review; risk is elevated because this is a hotspot” |
That last row is the litmus test. If the system cannot tell you what to do next, it did not really answer the question.
For agent workflows, the ideal response is not a paragraph of prose. It is a compact bundle of signals the model can act on:
- recent commit sequence
- ownership %
- co-change partners
- architectural role
- linked decision record
- related files or symbols
Tools like Sourcegraph, DeepWiki, and Repowise split these pieces differently, which is why buyers should test the answer shape rather than the marketing page. If you want a concrete pattern for repo-aware retrieval, cross-repo workspaces is the right extension once one repository is no longer enough.
What to ask before buying a codebase RAG system
The simplest way to separate chunk search from repo intelligence is to ask questions that force structure.
| Vendor question | What a weak system says | What a strong system should show |
|---|---|---|
| How is git history indexed? | “We support commits” | Depth is configurable, significant commits are surfaced, and churn/co-change are queryable |
| How is ownership computed? | “We infer it from authors” | Ownership % reflects actual change patterns, not just file authorship |
| How do you keep docs fresh after commits? | “We re-index periodically” | Freshness is tracked and stale docs are detected after commits |
| Can agents get graph context automatically? | “Use search first” | PreToolUse and PostToolUse hooks enrich retrieval and warn when context is stale |
| Can you answer beyond file search? | “We have semantic search” | The system can answer risk, why, dead code, and architecture questions |
| Do you support cross-repo workspaces? | “Not yet” | Repo boundaries are optional, with federated queries when the architecture crosses them |
The freshness question matters more than most teams expect. A repo-aware system that does not notice it is stale after a commit is only half a system. That is why agent hooks matter: retrieval should improve after the model acts, not wait for a nightly reindex.
If you are evaluating this category, ask about history depth, freshness, and cross-repo workspaces in the same breath. Then ask whether the system can answer a commit-understanding query without falling back to file search. If it cannot, it is not preserving enough structure.
The better products are moving toward that shape through better indexing, graph context, wiki layers, and hooks that keep the answer fresh. One implementation path is an MCP server with task-shaped tools and agent hooks; another is a search product with richer code intelligence. The common thread is the same: stop treating the repository like a bag of chunks.
agent hooks token efficiency benchmark
FAQ
What is codebase RAG and why does it fail on git history?
Codebase RAG is retrieval-augmented generation applied to source repositories. It often fails on git history because it retrieves current text chunks but loses the sequence of change that explains intent, churn, and regressions. Without history, the model can describe code but not why it became that way.
How do you evaluate ownership in a codebase RAG system?
Do not ask whether it can name an author. Ask whether it can show ownership %, active reviewers, co-change patterns, and likely blast radius for a subsystem. Ownership is about who actually changes and maintains the code, not who touched it once.
Is Sourcegraph enough for agent workflows?
Sourcegraph is a strong baseline for code search and code intelligence, especially when the question is “where is this symbol used?” For agent workflows, though, search alone is usually not enough. The agent also needs history, ownership, architecture, and freshness signals to avoid repeated reads and stalled edits.
What should a vendor return for a commit-understanding query?
It should return at least four things: history, ownership, architecture, and related files or symbols. A good answer also includes the reason for the change and the likely next action, so the agent can move forward without re-reading the same files.
How do you know if a system is really better than chunk RAG?
Give it a commit-understanding question and see whether it can explain the change using history, ownership, and architecture in one response. If it only returns a few matching snippets, it is still chunk RAG with a nicer wrapper.


