Leiden communities vs PageRank for code hotspots
A dependency graph will happily tell you two different truths about the same repository: which files sit on the busiest paths, and which files belong together. leiden community detection answers the second question; PageRank answers the first. If you use them interchangeably, you end up mistaking a bridge for a boundary or a boundary for a hotspot.
PageRank is the older, more familiar lie detector here. It does not tell you what a file is for. It tells you how much the graph seems to care about it.
PageRank on a code graph tells you which files are central, not which files belong together
PageRank is a centrality score over a graph. In a code dependency graph, that usually means import edges, call edges, or other directed relationships between files and symbols. A node gets a higher score when many important nodes point to it, or when it sits on paths that themselves matter.
That makes PageRank useful for code hotspots. If a file is imported by many modules, or if a helper sits underneath several frequently used paths, PageRank will push it toward the top. A concrete example: core/serializer.py may have high PageRank because half the codebase depends on its types and conversion helpers. It is central, and central often means expensive to touch.
But central is not the same as cohesive. A file can be globally important and still tell you almost nothing about module structure. A logging utility used everywhere may rank high even though it belongs to no meaningful subsystem boundary. A shared validator may be a hotspot and a dependency sink at the same time.
That is why PageRank is good for triage and weak for shape.
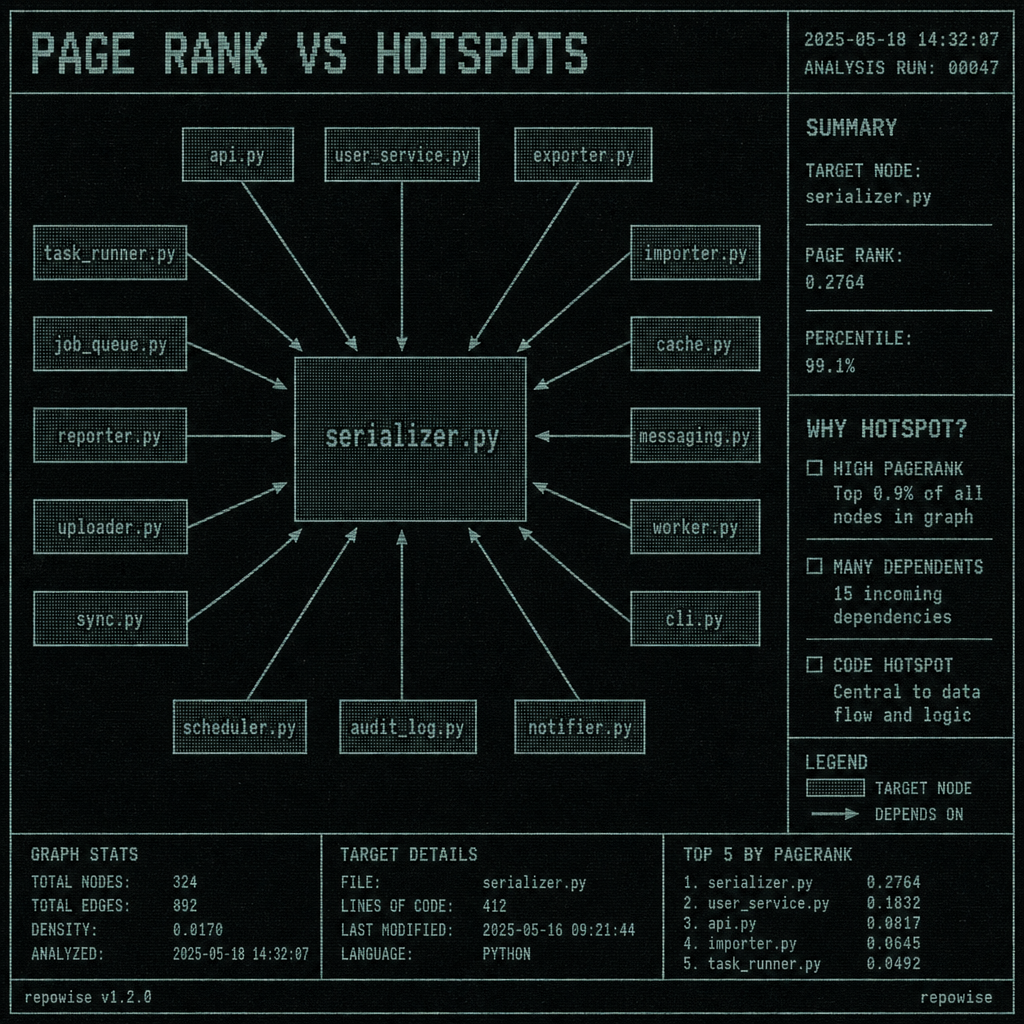 PAGE RANK VS HOTSPOTS
PAGE RANK VS HOTSPOTS
If you want the canonical reference, NetworkX documents PageRank as a centrality measure, which is exactly the right mental model for code graphs too: rank the nodes, do not partition them. dependency graph code hotspots
Leiden community detection groups the graph by dense internal ties and sparse external ties
leiden community detection is solving a different problem. Instead of ranking nodes, it partitions the dependency graph into communities that are more connected internally than externally. The practical outcome matters more than the algorithmic steps: you get clusters that often correspond to packages, subsystems, feature areas, or ownership seams.
That is why Leiden is useful for boundary questions. If a set of files call each other, import each other, and change together, they often belong in the same community even if none of them is individually famous. A cluster can span multiple files with moderate rank but strong internal linkage. That is usually the shape of a subsystem that wants to be understood as a unit.
The interesting part is not that communities exist. It is that they are often the answer to the question, “where should this refactor stop?”
A community boundary is a place where the graph gets thin. That can align with package boundaries, API surfaces, or teams. It can also reveal accidental architecture: a feature that is split across directories but still behaves like one thing.
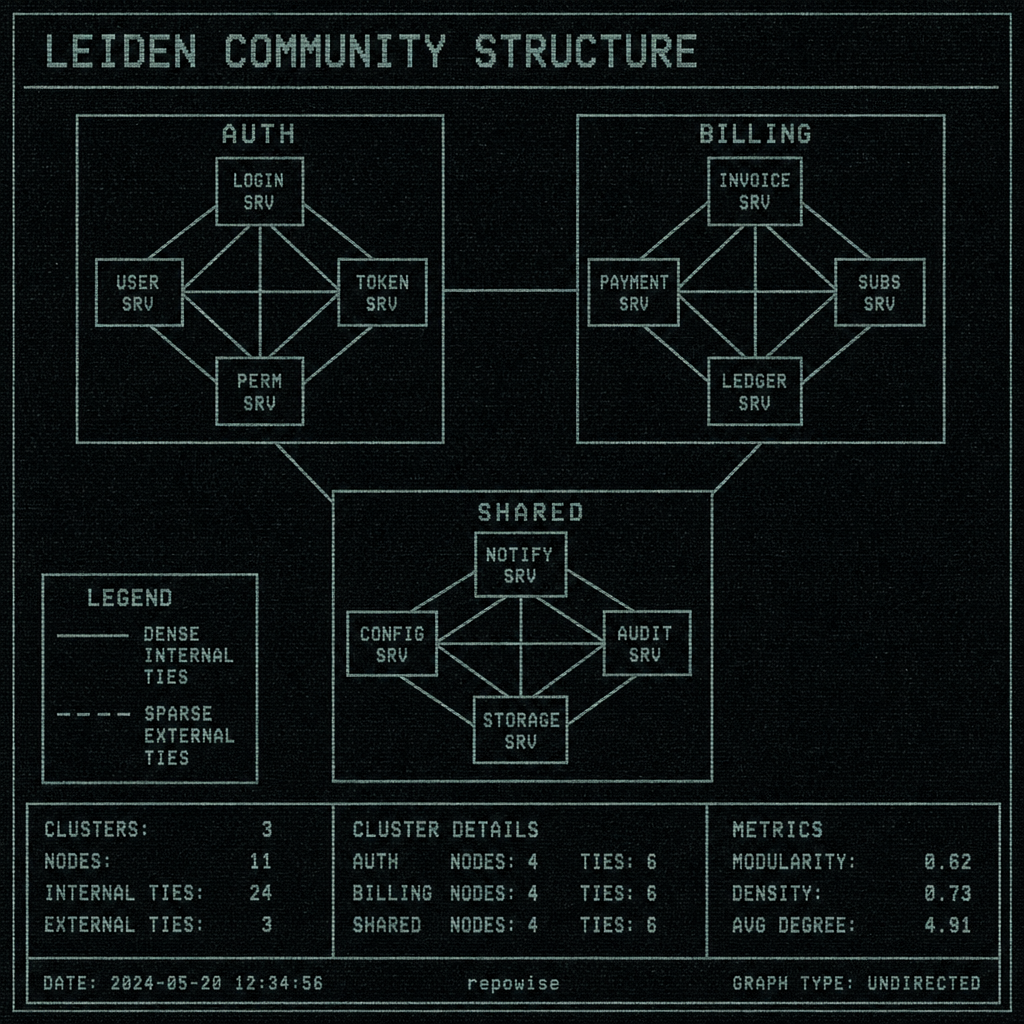 LEIDEN COMMUNITY STRUCTURE
LEIDEN COMMUNITY STRUCTURE
For a practical reference, NetworkX exposes leiden_communities, and the broader literature describes Leiden’s goal as finding well-connected communities rather than merely dense ones. That distinction matters in code, where a “community” that falls apart internally is not much help. tree-sitter parsing ownership mapping
Hotspots are not the same as communities: one is about concentration, the other about structure
This is where people usually blur the terms and lose something useful.
| Question | Graph output | What it is good for | What it misses | Example code task |
|---|---|---|---|---|
| Which files are most central? | PageRank ranking | Triage, risk, code hotspots | Module boundaries, cohesive subsystems | “What should we inspect first after a failure?” |
| Which files belong together? | Leiden communities | Ownership, coupling, refactor scope | Relative importance inside the cluster | “What is the smallest coherent unit to extract?” |
A hotspot can sit inside a community, on a boundary, or across several communities. A community can contain low-rank nodes that still matter as a unit because they share a purpose. That is the part people miss when they reduce graph analysis to “important files.”
The ownership angle is especially easy to get wrong. A file with high PageRank may be shared infrastructure maintained by everyone and owned by no one in particular. A community may map more cleanly to a team’s area of responsibility even if none of its files are individually central. If you are doing ownership mapping, coupling analysis, or planning refactor scope, the boundary often matters more than the rank.
We got this wrong initially in a small internal experiment: we kept asking for “the most important files” when what we actually wanted was the seam between two subsystems. The result was a lot of attention on shared utilities and not enough attention on the adapter layer that made the change expensive. Rank found the fire; community structure found the wall the fire was spreading through.
Worked example: the same repository can produce two different answers from the same graph
Consider a toy repository with eight files and these directed dependencies:
app.pyimportsauth.py,billing.py, andhelpers.pyauth.pyimportsmodels.pyandhelpers.pybilling.pyimportsmodels.py,payments.py, andhelpers.pypayments.pyimportsgateway.pyandhelpers.pygateway.pyimportshttp_client.pymodels.pyimportsdb.pyhelpers.pyimportsdb.pydb.pyimports nothing
A PageRank run over that dependency graph might produce a top-3 list like this:
| Rank | File | Why it ranks high |
|---|---|---|
| 1 | helpers.py | Shared by multiple modules and sits on many paths |
| 2 | db.py | Deep dependency with many inbound references |
| 3 | models.py | Used by both auth.py and billing.py |
Now run leiden community detection on the same graph. A plausible partition looks like this:
| Community | Files | Interpretation |
|---|---|---|
| A | app.py, auth.py, helpers.py, models.py, db.py | User-facing flow plus shared data path |
| B | billing.py, payments.py, gateway.py, http_client.py | Payment subsystem |
| C | helpers.py | Bridge node touching both communities |
The interesting file is helpers.py. Its PageRank is high because everyone uses it. But it is not the best refactor anchor, because it is not the boundary. The real seam is the adapter path between billing.py and payments.py, or between payments.py and gateway.py, depending on the change.
That is the whole point. PageRank tells you that helpers.py is expensive. Leiden tells you that the payment path is a boundary.
If you were planning a cleanup, the central utility might be where tests are brittle. The community boundary might be where the architecture is brittle.
Choose PageRank when you need priority; choose Leiden when you need boundaries
If the question is “what should we inspect first?”, use PageRank. If the question is “what belongs together?”, use leiden community detection.
| Task | Better method | Why |
|---|---|---|
| Incident triage | PageRank | Finds central files likely to affect many paths |
| Hotspot analysis | PageRank | Surfaces concentrated dependency pressure |
| Ownership mapping | Leiden | Clusters often align with team or subsystem boundaries |
| Refactor scope | Leiden | Helps define a coherent unit of change |
| Blast radius estimation | Both | Rank shows centrality; communities show where impact stays local or crosses boundaries |
| Module extraction | Leiden | Reveals the natural cut lines |
A useful rule of thumb: rank when you need priority, cluster when you need shape.
That also means the two methods are complementary in a healthy code-intelligence workflow. PageRank helps you decide where the pressure is. Leiden helps you decide where the seams are. One without the other gives you a half-answer.
How this shows up in Repowise’s graph intelligence layer
A graph-aware code system should expose both views, because agents ask both kinds of questions. Repowise’s graph intelligence layer does this over a tree-sitter-backed dependency graph: PageRank for centrality, Leiden communities for structure, plus retrieval surfaces like get_overview and get_context when an agent needs graph-aware context instead of another blind file read.
That distinction matters when an agent is deciding whether a change request is a hotspot problem or a boundary problem. If the prompt is “what is the most connected file here?”, centrality is the right answer. If the prompt is “what files form the subsystem around this change?”, communities are the right answer.
In practice, the best systems do not force a single graph view on every task. They expose the right one at the right time, then keep the other one close by for when the question changes.
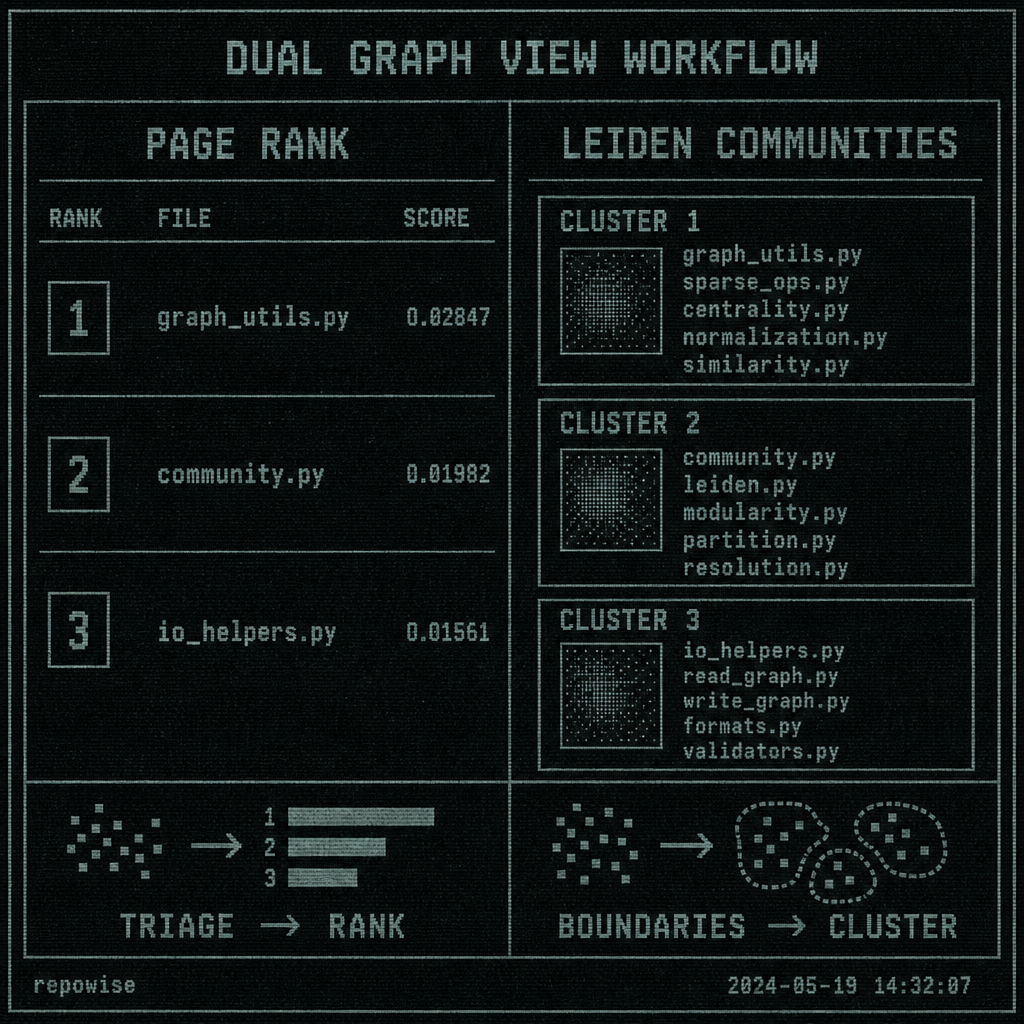 DUAL GRAPH VIEW WORKFLOW
DUAL GRAPH VIEW WORKFLOW
FAQ
What is the difference between PageRank and Leiden community detection in a code dependency graph?
PageRank ranks nodes by centrality, so it tells you which files are most connected to important paths. leiden community detection partitions the graph into dense groups, so it tells you which files belong together.
When should I use PageRank to find code hotspots?
Use PageRank when you need priority: incident triage, risky shared utilities, or files with many dependents. It is a good first pass for code hotspots because it surfaces central nodes quickly.
How does Leiden community detection help with refactor boundaries?
Leiden shows where the graph naturally clusters, which helps identify subsystem boundaries and coupling seams. That makes it useful for deciding refactor scope and estimating whether a change stays local or crosses communities.
Can a file have high PageRank but still not belong to the main community?
Yes. A file can be globally central because many modules depend on it, while still acting as a bridge between communities rather than living cleanly inside one. That is one reason PageRank and Leiden are complementary, not interchangeable.
