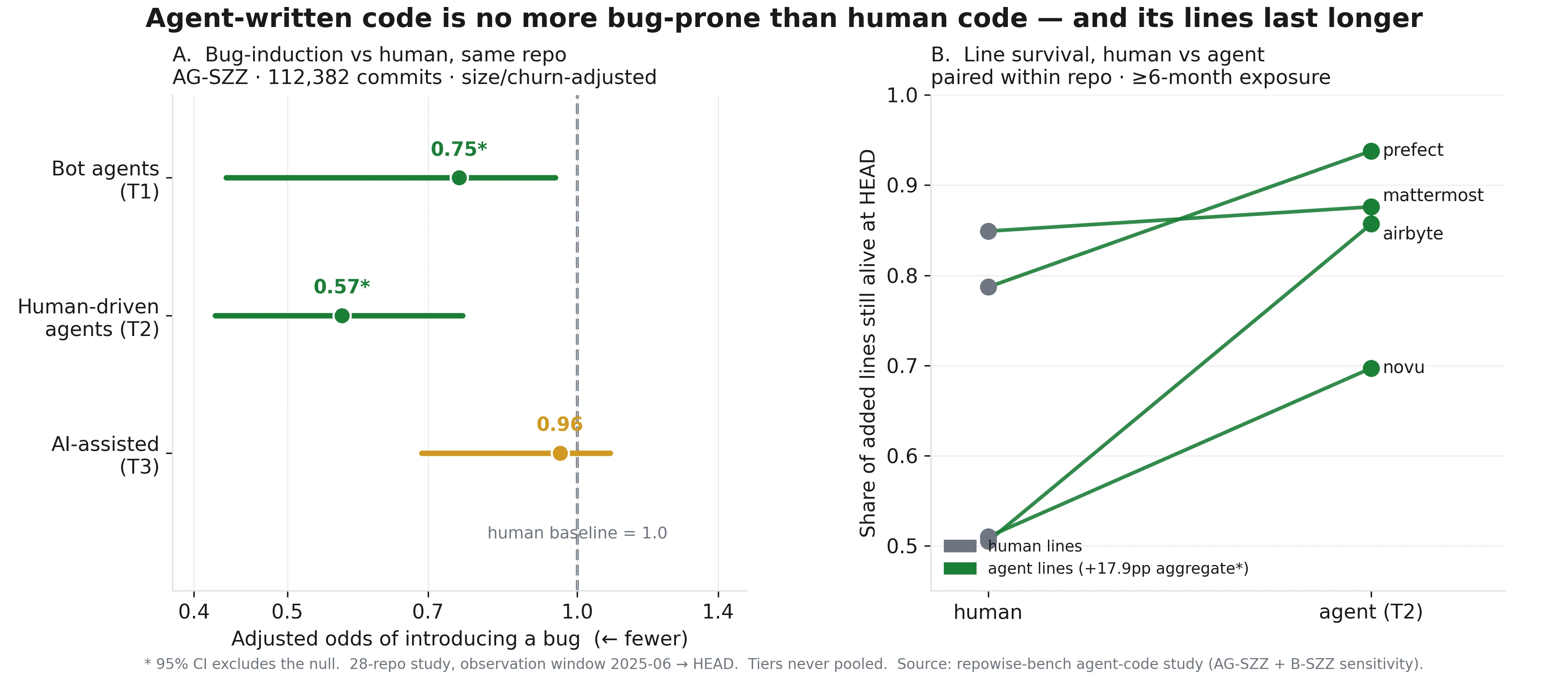
Our git co-change model failed on a monorepo refactor
The first time we trusted co-change analysis git on a monorepo refactor, the graph looked embarrassingly good. Dense edges. Clear clusters. A few files that seemed to move together often enough to feel like coupling, and enough git history to make the signal look statistically respectable. It was wrong in exactly the way history-based models tend to be wrong: the model learned migration artifacts, not architecture.
The graph looked right because the refactor created perfect-looking co-change pairs
The failure mode was simple. A monorepo refactor moved code between packages, updated imports, renamed modules, and cleaned up call sites in one sweep. On paper, that creates a beautiful co-change analysis git graph. Files that were only adjacent because of the migration now appear to have a long-standing relationship. Why files that moved together are not necessarily coupled is the whole trap.
History does not tell you why two files changed together. It only tells you that they did. In a small repo, repeated co-edits often do mean real coupling. In a monorepo, a single migration can create dozens of edges that look just as convincing as organically evolved ones. If you only look at raw co-change counts, the refactor can dominate the window and drown out the rest of the signal.
That is especially true when you use a fixed history window. A window can be dense and still be semantically wrong. If one refactor contributes 40% of the edges, the graph is not “more informed.” It is mostly describing the refactor.
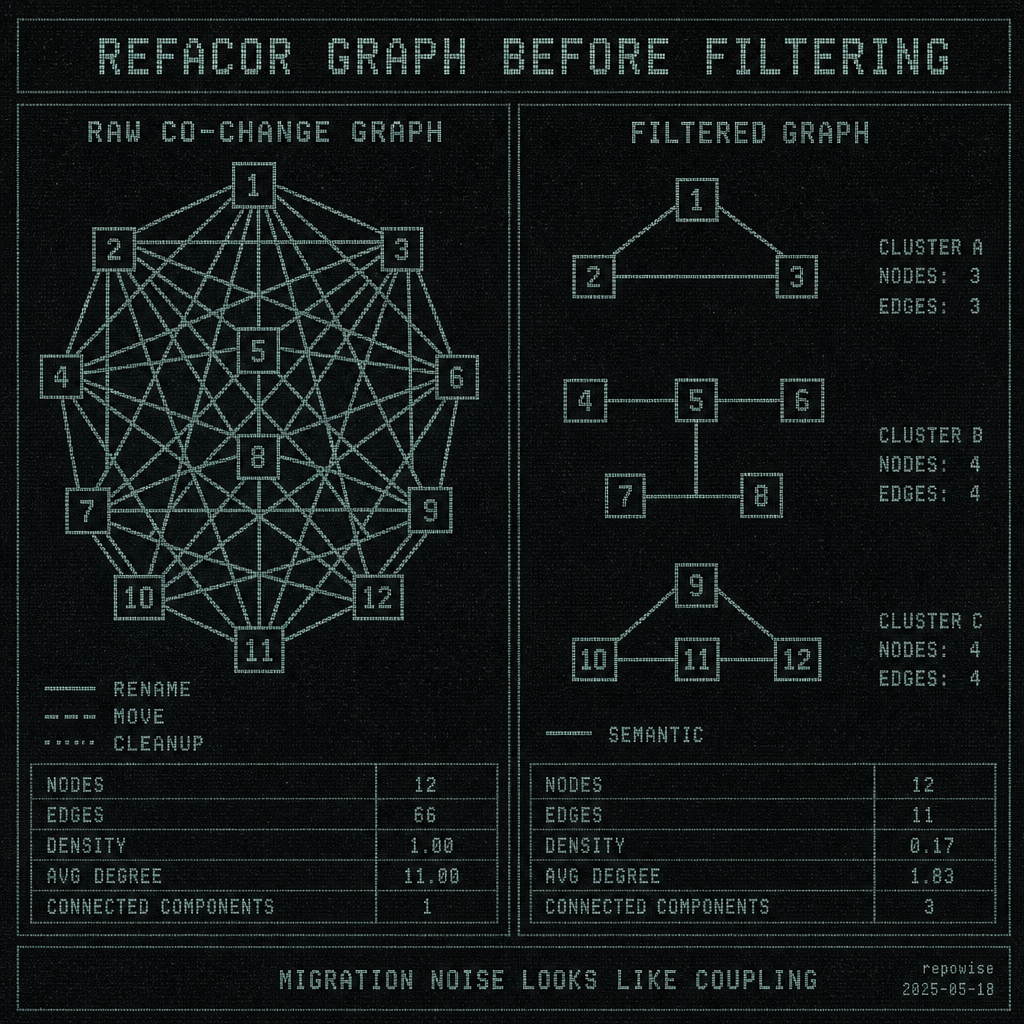 REFACOR GRAPH BEFORE FILTERING
REFACOR GRAPH BEFORE FILTERING
The academic framing for co-change analysis is not wrong. The classic empirical papers are asking a real question: when two files change together repeatedly, does that imply an evolutionary relationship? Yes, sometimes. But the result depends on the quality of the history. Monorepo history, at scale, is noisy by construction; Atlassian’s monorepo guidance says as much without being dramatic about it. The point is not that git history is useless. The point is that history needs interpretation before it becomes a coupling signal.
hotspots, ownership, and co-change pairs file and symbol graph
What the refactor actually changed in the data: rename storms, mechanical edits, and one-off cleanup commits
Once we inspected the commits behind the graph, the pattern was obvious in hindsight. The edges were coming from rename/move noise, mechanical commits, generated files or formatter churn, and a few dependency bumps that touched the same neighborhoods of the tree.
Here is the taxonomy we should have used earlier:
| Commit type | Typical effect on co-change | How we treat it |
|---|---|---|
| Refactor | Inflates many edges at once | Exclude from coupling scoring |
| Rename / move | Creates false adjacency between old and new paths | Track separately, don’t count as semantic coupling |
| Formatter-only | Touches many files with no design meaning | Down-weight aggressively or exclude |
| Generated | Rewrites large surfaces mechanically | Exclude unless the generated artifact is the subject of the question |
| Dependency bump | Creates broad package-level churn | Down-weight; often unrelated to ownership |
| Semantic change | Repeated, localized, meaningful edits | Count normally |
The surprising part was not that these commits distorted the graph. It was how little distortion it took. One large refactor can dominate a history window because co-change analysis git tends to reward breadth. A broad commit that touches 60 files creates more apparent relationships than 12 months of smaller, semantically clean changes.
That is why a monorepo refactor is dangerous to coupling inference. It compresses many architectural moves into a short span, and history-based scoring has no native way to tell “these files changed together because we moved them” from “these files changed together because they belong together.”
The same problem shows up in generated code. If a protobuf schema changes and the generated clients are checked in, every downstream file looks correlated with the schema. That is not ownership. It is propagation.
 COMMIT TAXONOMY FOR CO-CHANGE
COMMIT TAXONOMY FOR CO-CHANGE
We got this wrong initially because the raw counts were so tempting. A file pair with eight co-changes in 30 commits feels meaningful. But if six of those eight came from a single migration and one from a formatter sweep, the count is doing propaganda, not analysis.
A worked example: the false edge that sent planning down the wrong path
The easiest way to see the failure is with one edge that looked useful and wasn’t.
| File pair | Raw co-change count | Commit types contributing to the edge | Normalized score | Trusted? |
|---|---|---|---|---|
packages/payments/src/router.ts ↔ packages/billing/src/router.ts | 9 | 1 refactor, 4 rename/move, 2 formatter-only, 2 semantic | 0.18 | No |
packages/payments/src/router.ts ↔ packages/payments/src/rules.ts | 5 | 5 semantic | 0.84 | Yes |
The first pair looked stronger at a glance. Nine co-changes beat five. The graph placed the packages in the same community, and the planning doc followed suit. The team assumed the billing router was part of the same blast radius as payments router changes. That changed reviewer assignment, test planning, and who got paged for a follow-up fix.
It turned out to be migration noise. The two routers had been moved and renamed during the refactor, then massaged by a formatter and a dependency pin update. They were not sharing behavior. They were sharing a history window.
The operational cost of that mistake was not abstract. We sent the wrong reviewer to the wrong package, widened the blast radius in planning, and overestimated the risk of a change that was actually local. The later investigation was almost boring: the real dependency was within payments, not across the package boundary. The false edge had simply been louder.
This is the part that matters for teams using AI agents and automation. If your tooling reads the graph as a source of ownership, it will faithfully amplify the wrong relationship. The graph does not just suggest where to look. It can also steer a plan toward the wrong code path.
why a change was made
The fix: separate churn from coupling before you score co-change
The right response was not to abandon co-change analysis git. It was to stop treating every co-change as evidence of coupling.
We added guardrails in the scoring pipeline:
- Exclude pure refactors.
- Down-weight rename-only commits.
- Normalize by file churn, not just raw co-change count.
- Require semantic overlap before an edge is trusted.
- Treat large multi-file sweeps as a separate class of event.
The key idea is boring but effective: score co-change after filtering or normalizing for churn, not before.
A practical implementation looks like this:
- If a commit touches many files but changes little semantic surface area, it should contribute less.
- If a commit is mostly renames or moves, preserve the provenance but do not let it create strong coupling.
- If two files only co-appear inside a single migration window, mark the edge as suspicious until repeated semantic co-edits show up later.
The phrase “semantic overlap” matters. We used it as a thresholding rule, not a vibe. Did the same files keep changing for the same reason? Did the edits land in the same function, schema, or decision boundary? If yes, the edge can earn trust. If not, it stays on probation.
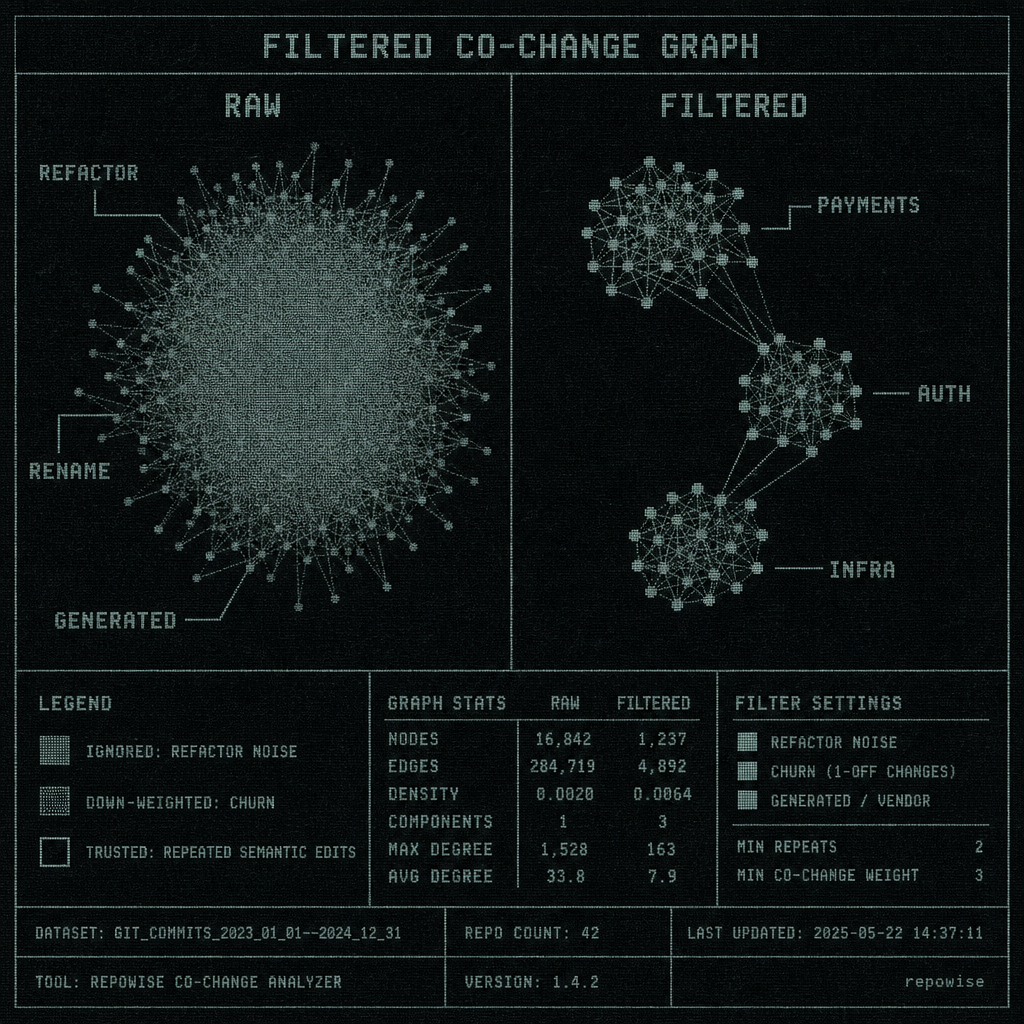 FILTERED CO-CHANGE GRAPH
FILTERED CO-CHANGE GRAPH
This is where tools like Repowise, Sourcegraph, and other code intelligence systems start to matter. The useful ones do not just expose a graph. They let you ask for context around the graph, then decide which edges deserve trust.
Which filters were worth the complexity, and which ones were not
We tried a few things that sounded smart and only some of them survived.
| Mitigation | Precision | Recall | Operational cost | Kept? |
|---|---|---|---|---|
| Exclude pure refactors | High | Medium | Low | Yes |
| Track renames separately | High | High | Medium | Yes |
| Down-weight churn-heavy commits | Medium | Medium | Low | Yes |
| Require repeated semantic co-edits | High | Lower | Medium | Yes |
| AST-level diff similarity across files | Very high | Low | High | No |
| Commit-message classification with an LLM | Medium | Medium | High | No |
| Manual allowlist of “important” files | High | Low | Very high | No |
The tradeoff is always precision vs recall. If you filter too aggressively, you miss real coupling that happens to appear in noisy commits. If you filter too loosely, you keep the migration artifacts and misread the graph. We chose to bias toward precision for ownership and blast radius use cases, because false positives are more expensive there than false negatives.
The more sophisticated ideas were not worth shipping. AST-level diff similarity sounded elegant, but it was expensive to maintain and brittle across languages. LLM commit classification worked until it didn’t, and then we had to explain why a model thought a generated file was “semantically meaningful” because the commit message was vague. Manual allowlists were worse: they institutionalized exceptions instead of fixing the signal.
The guardrails we kept are mostly cheap. That matters. If the filters require a separate human review loop, they will not survive contact with a fast-moving monorepo.
Where co-change still earns its keep in a monorepo
The useful case is still the original one: repeated, localized, semantically meaningful edits.
Co-change becomes meaningful when:
- the same files change together across multiple unrelated commits,
- the edits happen outside refactor windows,
- the changes are small enough that they are likely about behavior, not migration,
- the relationship survives renames, formatter sweeps, and dependency churn.
That is when co-change analysis git is actually telling you something about coupling. A stable module boundary that keeps getting edited together is a real signal. A pair of files that repeatedly break together during bug fixes is a real signal. A package that consistently shows up in the same blast radius as another package, after you remove the migration noise, is a signal worth using for ownership and reviewer routing.
This is also where co-change pairs help with reviewer assignment. Not “who touched these files once during the refactor,” but “who keeps touching the same behavioral surface.” That distinction is the difference between a graph that helps planning and a graph that just mirrors the last migration.
The best test is simple: if you removed the largest refactor from the history window, would the edge still exist? If yes, trust it more. If no, it was probably migration noise wearing a coupling costume.
FAQ
How do you tell whether co-change analysis git is real coupling or refactor noise?
Look for repetition outside the refactor window. Real coupling shows up as repeated semantic co-edits across multiple commits, not just a single dense migration event. If the edge disappears when you exclude rename-heavy or formatter-only commits, it was probably noise.
What should you filter out before trusting co-change pairs in a monorepo?
Start with pure refactors, rename/move noise, formatter-only commits, generated file churn, and broad dependency bumps. Those are the usual sources of false edges. Then normalize by churn so one large commit does not dominate the score.
Can co-change analysis be used for ownership and blast radius in a large repo?
Yes, but only after guardrails. It works well when you use it as one input among several, especially for repeated semantic edits and stable module boundaries. Used raw, it will misassign owners and overstate blast radius after a monorepo refactor.
When does git co-change analysis stop being useful?
It stops being useful when the history window is dominated by migration artifacts, generated churn, or broad mechanical sweeps. At that point the graph tells you more about how the repo was reorganized than how the code is coupled. The signal comes back once you filter or normalize for churn.
How do you tell whether co-change pairs are trustworthy enough for planning?
Ask whether the pair survives three checks: it appears in more than one non-refactor commit, the changes are semantically related, and the edge remains after you remove rename-only and mechanical commits. If all three are true, it is probably safe to use for planning, reviewer routing, or blast-radius estimates.