Codebase intelligence is becoming the missing layer for agents
An agent can read every file in a repo and still make the wrong change. That is the failure mode behind most agent context gaps: the model has access to text, but not to the structure that tells it which files matter, who owns them, what changed recently, or why the code exists at all. The emerging codebase intelligence category is the answer to that gap, and it is becoming the missing layer between the LLM and the repo.
The distinction matters because “can open files” is not the same as “can work a codebase.”
Why file readers keep failing once agents leave toy repos
A file reader is fine when the task is local: change one function, update one test, ship one patch. It breaks when the task spans modules, recent refactors, or code with hidden coupling.
Here is the classic failure mode. A bug report says “checkout totals are wrong for subscription upgrades.” The agent searches for checkout, finds a billing helper, edits the first obvious file, and writes a test that passes locally. The real bug lives in a caller two layers up, where a discount path bypasses the helper entirely. The agent edited the wrong file because it lacked importer/caller context.
That is not a model deficiency. It is a context acquisition problem.
Raw file access gives you a pile of text. Task-shaped context gives you the right slice of the repo for the job: the impacted symbols, the callers, the owners, the recent commits, the adjacent docs, and the decisions that explain why the code looks strange. agent context engineering is increasingly the difference between “agent wrote something” and “agent finished the task.”
The practical contrast looks like this:
| Task | Raw file access | Git diff only | Codebase intelligence layer |
|---|---|---|---|
| Find impacted files | Search terms, hope for the best | Only sees changed lines | Uses graph and callers to surface likely blast radius |
| Identify owner | Maybe grep for comments | Maybe infer from recent edits | Uses ownership signals and co-change history |
| Explain why this code exists | Reads current implementation | Sees what changed, not why | Pulls architectural memory and linked decisions |
| Estimate blast radius | Guess from imports | Guess from changed files | Uses dependents, communities, and hotspots |
| Answer with citations | File lines, if any | Patch hunks, if any | Returns provenance-backed context and cited answers |
The point is not that file reading is bad. The point is that file reading is too blunt for agents that are expected to reason across a living repo.
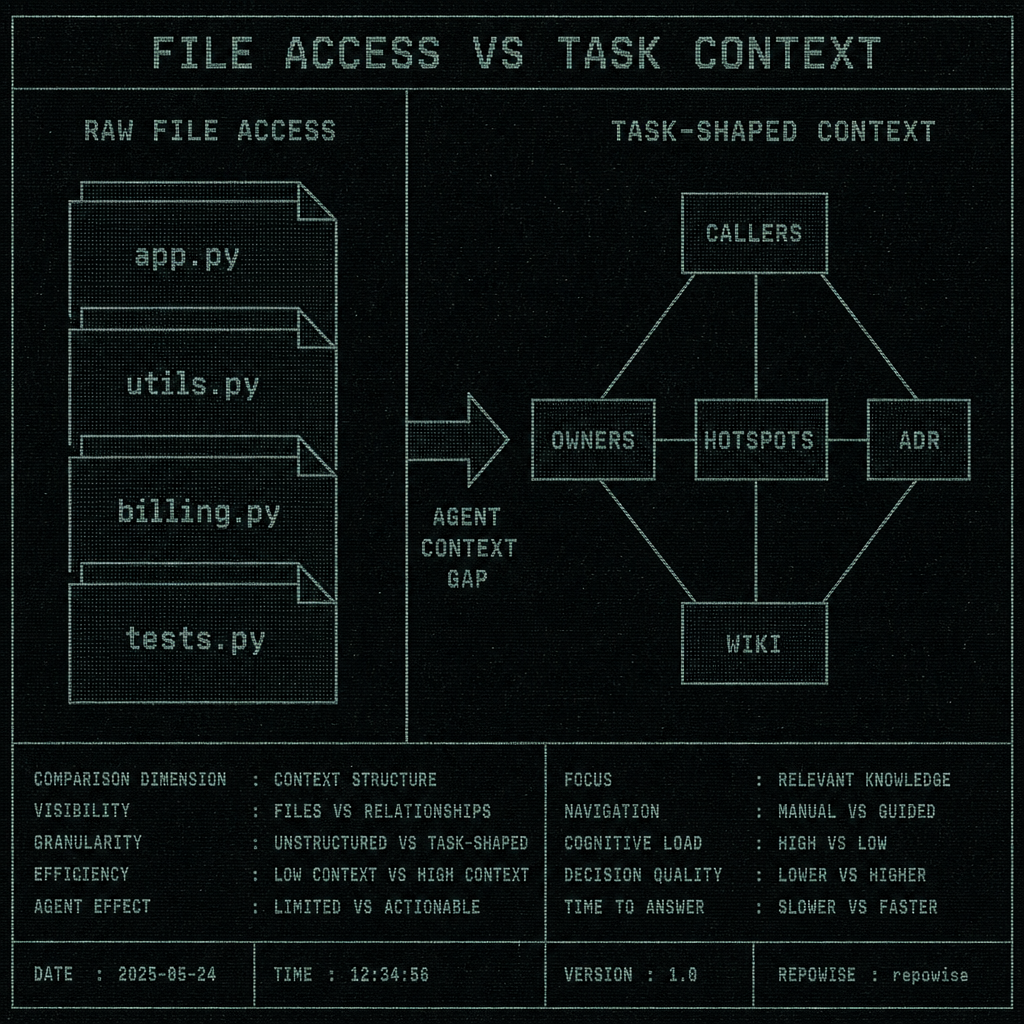 FILE ACCESS VS TASK CONTEXT
FILE ACCESS VS TASK CONTEXT
The missing layer is not another prompt trick; it is a codebase intelligence category
The codebase intelligence category is an intermediate layer that turns a repository into queryable structure, memory, and decision context for agents. It is not just search. It is not just embeddings. It is not just a better prompt.
It is the thing that lets an agent ask: what is this code connected to, who touches it, what changed around it, and what decision made it this way?
That makes it different from MCP too. MCP is transport, not the intelligence layer. The Model Context Protocol standardizes how tools are exposed to a model; it does not decide which files are related, what counts as an owner, or how to summarize a stale architectural decision. If you want a clean mental model, think of MCP as the road and the codebase intelligence category as the city map, traffic model, and address book.
This is also why vendors and internal tools belong on the same map. A company can buy a hosted product, build an internal index, or mix the two. The category is the abstraction worth evaluating. The implementation is a separate question.
A useful codebase intelligence layer usually starts with a graph index: files, symbols, imports, callers, callees, entry points, and communities. From there it can answer where to look first, what depends on what, and what the likely blast radius is. MCP is the transport, not the memory is the right instinct for this category: the transport matters, but it does not create memory by itself.
What surprised a lot of teams the first time they tried this is how often the agent does not need “more code.” It needs less code, but the right code. The difference shows up immediately in tool calls.
 TASK-SHAPED TOOL REGISTRY
TASK-SHAPED TOOL REGISTRY
What the layer has to know: graph, git history, architectural memory, and docs
A useful system needs more than one substrate because each answers a different agent question.
The graph index answers “where is this connected?” It tells you the module map, the entry points, the importers, the callers, the callees, and the structural communities. If you have ever watched an agent edit a helper while the real behavior lived in a higher-level caller, you have seen why graph data matters.
Git history answers “what changed, and what patterns repeat?” With enough history, you get hotspots from churn × complexity, ownership percentages, co-change pairs, bus factor, and significant commit messages. That is how an agent learns that a file is not just important; it is fragile, or frequently touched, or usually edited with another module.
Architectural memory answers “why does this exist?” This is where decision records, inline markers, and commit-derived decisions matter. Without that layer, agents can only infer intent from current code, which is how they end up “fixing” a deliberate tradeoff.
Docs answer “what should I trust right now?” Wiki pages and ADRs are only useful if they are freshness-scored or staleness-tracked. Stale context is worse than no context because it gives the model confidence in the wrong direction.
Ownership signals matter for the same reason. When an agent knows the likely reviewer, maintainer, or recent contributor, it stops guessing whom to ask and where to look. ownership and bus factor is not a people-process add-on here; it is part of the retrieval problem.
The minimum useful system usually has to answer four questions:
- Where should I start?
- Who owns this?
- What changed recently?
- Why was it built this way?
If it cannot answer those, it is not doing codebase intelligence. It is doing prettier search.
A worked example: how the same commit looks with raw files, git diff, and an intelligence layer
Take a small bug-fix scenario from pallets/flask: a recent commit changes request handling, and a later issue reports a regression in one code path. The task is not “read the diff.” The task is “understand the commit enough to know what else it touched.”
Here is how three strategies behave.
| Strategy | What the agent does | Tool calls / rereads | Result |
|---|---|---|---|
| Raw file reads | Greps for the bug text, opens several files, rereads dependencies by hand | High | Often lands in the wrong module first |
| Git diff only | Reads the patch, checks nearby hunks, infers impact from changed lines | Medium | Better than raw files, but blind to callers and ownership |
| Codebase intelligence layer | Starts with graph context, checks impacted symbols, pulls history, ownership, and docs, then answers with citations | Low | Faster path to the right module and fewer wrong-file edits |
The benchmark numbers make the difference concrete. On the pallets/flask token-efficiency run, the naive strategy used 64,039 tokens per commit on average, git diff used 14,888, and the intelligence layer used 2,391. That is 209× better than naive on the mean, 41.7× better than git diff on the mean, and 26.8× better on pooled tokens versus naive. On the SWE-QA benchmark, the same style of system cut tool calls by 49% and files read by 89%, with parity answer quality at roughly -0.01.
That is the real story. Not “the model got smarter,” but “the model had to read less irrelevant stuff.”
A short investigation walkthrough makes it clearer:
- The bug report mentions a failure in one endpoint.
- The agent asks for graph context around that endpoint and sees the caller chain.
- It checks git history for the touched module and finds a recent refactor.
- It pulls ownership and co-change data to see which adjacent file usually moves with it.
- It reads the wiki page and ADR linked to the subsystem.
- It edits the caller, not the helper.
That is the kind of path a codebase intelligence layer shortens. Raw file search usually does not.
 COMMIT INVESTIGATION FLOW
COMMIT INVESTIGATION FLOW
How to evaluate codebase intelligence without buying a demo
The wrong way to evaluate this category is to ask for a canned search query and watch a polished answer. The right way is to give it a real task and see whether it reduces rereads, wrong-file edits, and tool calls.
A staff engineer’s evaluation script should sound like this:
- Can you answer a bug or refactor task on my repo without me telling you which files matter?
- Where does the answer come from, and can you cite it?
- How fresh is the context, and what happens when the wiki or decision record is stale?
- Can you tell me who owns the affected area, or at least the likely reviewer?
- Can you show cross-repo impact if the change touches multiple services?
- How many files did the agent read, and how many times did it backtrack?
- Can I test this on a live task instead of a benchmark prompt?
Provenance and citations are not a nice-to-have here. If the system cannot tell you why it thinks something is true, it is hard to trust the answer when the repo is messy.
Cross-repo support is a real differentiator for teams with services, packages, and shared APIs. The moment a bug crosses repository boundaries, single-repo search starts acting like a local optimizer. You need federated scope, co-change across repos, and some way to match provider and consumer contracts.
Also ask whether the system treats freshness as a requirement. If the answer is built on stale docs and old decisions, the agent may be very confident and very wrong. That is a bad trade.
automated code review for AI agents is a useful adjacent lens here, because the same questions show up in review: what changed, what depends on it, and what context is missing?
Where Repowise fits in this category, and where it does not
Repowise is one concrete implementation of the codebase intelligence category. It combines four layers: graph intelligence, git intelligence, documentation intelligence, and decision intelligence. It exposes that through task-shaped tools like get_overview, get_context, get_risk, and get_why, plus search and dead-code analysis. It can run self-hosted or hosted, and it supports multi-repo workspaces when the task crosses boundaries.
That makes it a fit for teams that want an open-source, self-hostable layer between their agents and their repos, especially if they care about ownership, history, architectural memory, and cross-repo work. It is also a fit if your agents already live in Claude Code, Cursor, Cline, or another MCP-compatible environment and you want the tools to feel task-shaped rather than like a pile of generic endpoints.
It is not the right answer if you only need a narrow point solution. If all you want is code search, or a lightweight doc index, or a single-purpose review bot, the full category may be more than you need. Some teams will want a managed service. Some will want to build their own graph and keep the rest in-house. Some will want both.
A few implementation details matter because they show where the category is headed. Repowise’s PreToolUse hooks can enrich Grep and Glob with related files before the agent even asks. Its PostToolUse hook can flag stale wiki content after a commit. That is the kind of behavior that separates a passive index from an active intelligence layer.
why embeddings alone are not enough for code is another useful comparison point, because vector search helps with recall but does not replace structure, ownership, or decision memory.
The buyer question is not “do I want search?” It is “do I need a feature, a point solution, or a platform layer?” If your agents are already paying the tax of rereads, wrong-file edits, and missing history, the category is probably the right unit of purchase.
FAQ
What is the codebase intelligence category?
It is an intermediate layer that turns a repository into structured context for agents. Instead of handing an LLM raw files, it supplies graph structure, git history, ownership signals, docs, and architectural memory so the agent can answer task-specific questions with less guesswork.
How is codebase intelligence different from MCP?
MCP is a transport standard for exposing tools to models. Codebase intelligence is the substrate behind those tools: the graph index, history, docs, decisions, freshness, and provenance that make the tools useful. One moves context around; the other decides what context exists.
Do AI coding agents need git history and ownership data?
Yes, if they work on real repos. Git history tells the agent what changed, what tends to co-change, and where the hotspots are. Ownership data helps it find likely reviewers and the right adjacent files faster than blind search.
How do you evaluate a codebase intelligence platform?
Use a real task from your repo, not a canned query. Check whether it reduces rereads, wrong-file edits, and tool calls, and whether it can cite provenance, surface freshness, and handle cross-repo scope when needed.
Is a vector store enough for codebase intelligence?
Usually not. Embeddings help search, but they do not encode callers, ownership, commit history, or architectural decisions well enough to stand alone. For code, structure and memory matter as much as semantic recall.


