What Model Context Protocol actually sends to Claude Code
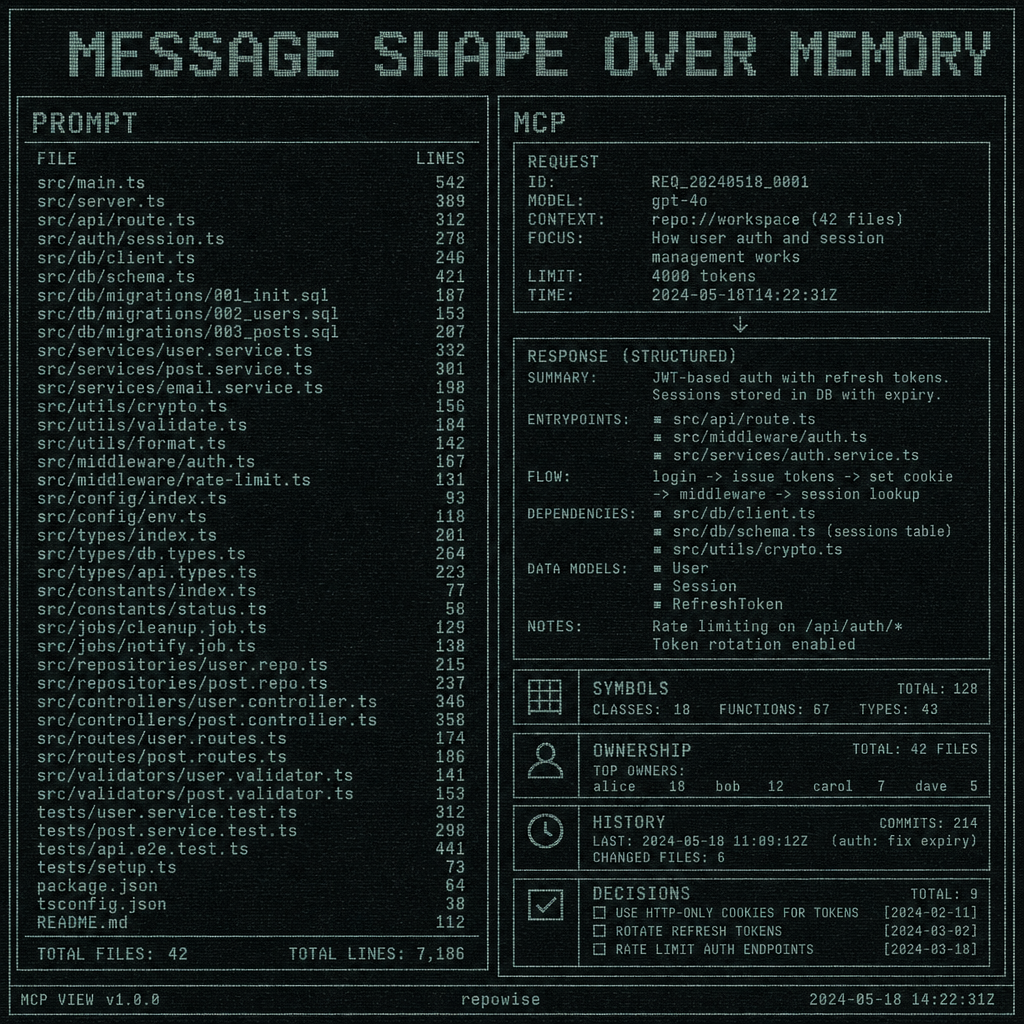
Claude Code does not “remember” your repository. It asks for context, gets back structured data, and keeps going. That is the practical shape of the model context protocol: a request/response interface for codebase context, not a magic memory layer. Once you think in protocol messages and tool calls, a lot of agent behavior stops looking mysterious and starts looking like ordinary API design.
MCP is a message protocol, not a magic memory layer
The useful mental model is boring in the best way: a client sends a message, a server answers, and the model reasons over that exchange. The model context protocol is the contract that defines what can be asked, what can be returned, and how much structure survives the trip.
That matters because the real problem is not “can Claude Code read the repo?” It is “what exact data can Claude Code request without rereading the same files five times?” MCP as an interface contract The protocol reframes codebase context as an interface problem. If the client can ask for symbol ownership, history, related docs, or architectural decisions, then the model does not need to infer all of that from raw text every time.
Claude Code is the concrete client most engineers care about because it sits in the loop where this pain shows up. It is not special because it is mystical. It is special because it is a real agent that can speak MCP and therefore can ask for context in a shape that is smaller, higher-signal, and more reusable than “read these 14 files.”
 MESSAGE SHAPE OVER MEMORY
MESSAGE SHAPE OVER MEMORY
What an MCP server exposes to a client
A useful MCP server exposes a small surface area, not a giant pile of ad hoc endpoints. The core categories are tools, resources, and prompts.
Tools are callable actions with explicit inputs and outputs. Resources are retrievable objects the client can inspect, usually by URI-like identifiers. Prompts are reusable templates or instructions the client can surface to the model. The client does not just “connect” and hope for the best. It first discovers what the server offers, inspects schemas and metadata, and then decides what to call.
That discovery step is the quiet part people skip when they talk about MCP as if it were a plugin system. It is not enough that a server exists. The client needs to know the shape of the contract before it can safely call anything. That is why schema matters so much here: the model can only make a good tool call if the client knows the tool’s input fields, what is required, and what the server will return when things go well or badly.
This is also where the protocol starts to feel like ordinary software engineering. If a tool says it returns “module summary, callers, ownership, freshness, related docs,” that is a much better contract than “here is some text.” The model can reason over structure. It cannot reliably reconstruct structure after you flattened it into a blob.
agent ergonomics for codebases codebase context
A tool call on the wire: request, arguments, result, and failure
Here is the shape that matters. Not the branding, not the setup, just the wire contract.
{
"jsonrpc": "2.0",
"id": "42",
"method": "tools/call",
"params": {
"name": "get_context",
"arguments": {
"target": "payments.router.route_charge",
"include": ["source", "callers", "callees", "ownership", "freshness", "docs"]
}
}
}
A server response is not “some vibes.” It is structured output the agent can use immediately.
{
"jsonrpc": "2.0",
"id": "42",
"result": {
"content": [
{
"type": "text",
"text": "payments.router.route_charge dispatches charge requests to card and wallet handlers."
},
{
"type": "json",
"json": {
"symbol": "payments.router.route_charge",
"module": "payments/router.py",
"callers": ["api.v1.checkout.submit_charge", "jobs.reconcile.retry_failed_charge"],
"callees": ["payments.handlers.card.charge_card", "payments.handlers.wallet.charge_wallet"],
"ownership": [
{"team": "checkout", "pct": 72},
{"team": "payments", "pct": 18}
],
"freshness": {
"wiki": "high",
"last_updated_commit": "a1b2c3d"
},
"docs": [
"Charge routing overview",
"Wallet fallback behavior"
]
}
}
]
}
}
And when it fails, the failure should still be useful. A good protocol does not collapse into “tool error, try again.” It gives the client enough shape to recover.
{
"jsonrpc": "2.0",
"id": "43",
"result": {
"content": [
{
"type": "text",
"text": "No direct symbol match for payments.router.route_charge."
}
],
"isError": true
}
}
That failure mode is important. The agent can fall back to a broader search, ask for the parent module, or request related symbols. The point is not that every query succeeds. The point is that the protocol preserves enough structure for the next move to be targeted instead of blind.
| Approach | Signal quality | Token cost | Likelihood of rereading the same files |
|---|---|---|---|
| Raw file reads | Low to medium | High | High |
| grep / glob | Medium for exact text, low for intent | Medium | Medium to high |
| MCP tool call | High when the server exposes the right context | Low to medium | Low |
What surprised us initially was not that structured context was better. It was how often the failure was in the shape of the response, not the amount of text. If the server returns the right symbols and relationships, the agent often does not need the source file at all.
 TOOL CALL ON THE WIRE
TOOL CALL ON THE WIRE
Why codebase context fits MCP better than files
Repository understanding is usually not a file-reading task. It is a query task.
When an engineer asks “what owns this change?” or “what breaks if I touch this symbol?” they are not asking for the full contents of the file. They want a compact answer synthesized from symbol graphs, ownership data, history, decisions, and documentation. Raw files are one representation of the codebase. They are not the right unit of context.
That is why prompt size is the wrong unit. A 200-line file can be less useful than a 20-field response that tells you who owns the symbol, which modules depend on it, whether it changed recently, what docs describe it, and which decisions explain it. The model context protocol is a better fit because it carries structured context, not just text.
This also changes how you think about freshness. A file can be current and still be useless as context if it lacks the surrounding graph. A decision can be stale and still matter because the code still reflects it. A good server lets the client ask for those specific dimensions instead of forcing the model to infer them from a blob of source.
If you have ever watched an agent reread the same three files because it could not tell which one mattered, you have already seen the problem. The fix is not “more prompt.” It is “better query surface.” why MCP is not just file access
Where agents use MCP differently from grep and glob
grep and glob are local search primitives. They answer “where does this text appear?” and “which paths match this pattern?” That is useful, but it is still a text-finding workflow.
MCP calls can return precomputed context, related symbols, ownership, and summaries that are already shaped for reasoning. That changes the next move. Instead of searching, reading, and then searching again, the agent can ask for the module context around a symbol and immediately get a higher-signal answer.
A good agent behavior looks like this:
- A change touches
billing.pricing.calculate_discount. - The client triggers a pre-tool enrichment step.
- The server returns top related symbols, callers, owners, and docs.
- The model updates its plan before it reaches for grep.
That kind of enrichment is why hooks matter. A PreToolUse-style step can intercept a low-level search request and attach likely related files or symbols before the model spends another round rediscovering the same neighborhood. It is not magic. It is just reducing avoidable rereads.
User: "Why did this pricing change fail tests?"
Agent: asks MCP for context on billing.pricing.calculate_discount
Server: returns callers, ownership, recent docs, and related decisions
Agent: inspects the returned context, then reads one or two files instead of the whole tree
The payoff is not only fewer tokens. It is fewer tool calls, fewer dead ends, and less churn in the agent’s working set. That matters because agents are often slow in exactly the places humans are slow: they over-read, then over-correct, then read again.
 SEARCH IS NOT CONTEXT
SEARCH IS NOT CONTEXT
What this means for Claude Code and Cursor in a real repo
Claude Code and Cursor are both better when the server can carry repository context cleanly. The question is not whether they support MCP in some abstract sense. The question is whether a given server can answer the kinds of repository questions your team actually asks.
A staff engineer should judge a server on one concrete criterion: can it answer a changed-symbol question without forcing the agent to reread the whole tree? If the answer is yes, you probably have something useful. If the answer is “it can list files,” you probably do not.
A short scenario is enough to see the difference. A pull request changes auth/session.ts. Claude Code asks the server for context on the changed symbol, gets back callers, ownership, related docs, and a recent decision, then reads one targeted implementation file. Cursor can do the same if the server exposes the right contract. The agent stays in query mode instead of falling back into file soup.
That is the real adoption test: not whether MCP exists, but whether the server reduces rereads and tool calls while preserving answer quality. If it does, the protocol is doing work. If it does not, you have a nicer name for a search index.
Tools like Repowise, Sourcegraph, and DeepWiki implement this differently, but the evaluation is the same: can the client ask for the right context, and does the server return it in a shape the model can use? Claude Code
FAQ
What does Model Context Protocol actually send to Claude Code?
It sends structured protocol messages: discovery, tool definitions, tool calls, and tool results. Claude Code is the client that issues the requests; the server returns data in the shape the tool contract defines.
How does an MCP tool call work on the wire?
The client sends a request with a tool name and arguments, usually through JSON-RPC-style messaging. The server responds with structured content or an error, and the model reasons over that response instead of guessing from raw files.
Is Model Context Protocol just a way to read files?
No. A file reader gives you bytes or text. The model context protocol can expose tools, resources, and prompts, plus structured results like symbols, ownership, history, and decisions. File access is one possible capability, not the point.
Why is MCP better than grep for codebase context?
grep finds text matches. MCP can return precomputed context that already answers the next question: who owns this symbol, what calls it, what changed recently, and which docs or decisions matter. That usually means fewer rereads and fewer tool calls.
What should I look for before adopting an MCP server?
Ask whether the server can answer a real repository question without dumping raw files. If it can return symbol-level context, ownership, freshness, and related decisions in a predictable schema, it is probably useful. If it only wraps search, it is not much more than grep with ceremony.


