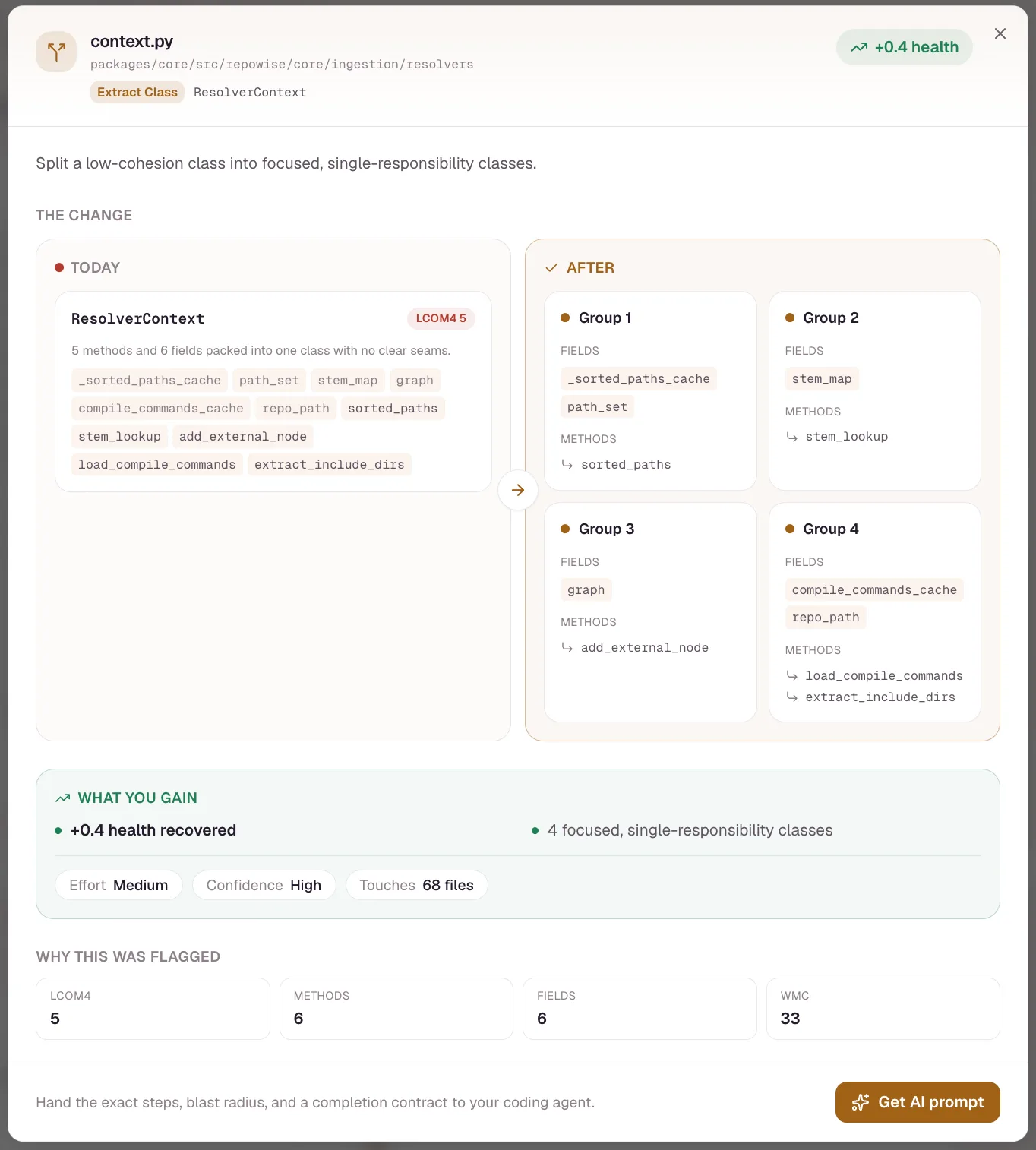
The only code-health score proven to predict real bugs.
21 deterministic markers score every file 1 to 10. The weights are calibrated against a real defect corpus, validated cross-project, and run in under 30 seconds on a 3,000-file repo. No LLM, no cloud.
Most code-quality tools hand you a score and ask you to trust it. None of them show whether the score actually finds the bugs.
A maintainability number is only useful if the files it flags are the files that break. repowise treats that as a measurable claim, validates it against real defect labels, and publishes the result, head to head and on your own repo.
A score you can defend in review.
Deterministic, calibrated against real defects, and open from end to end.

One score, 21 deterministic signals
Each file is scored from structural, behavioral, and historical signals, not a single complexity number. The weights are learned offline from a defect corpus, so the score reflects what actually predicts bugs rather than what is easy to measure.
- McCabe complexity, deep nesting, brain methods, LCOM4 cohesion, god classes
- Rabin-Karp clone detection and DRY violations
- Change entropy, co-change scatter, function-level churn, code-age volatility
- Ownership dispersion and prior-defect history
Measurably better than the leading commercial tool
On the same 2,770 files across 9 languages with real defect labels, ranking by repowise health surfaces 2.3x the defects under the same review budget. The lift is paired and statistically significant.
- Recall at a 20%-of-lines budget: 0.173 vs 0.074
- Effort-aware ranking (Popt): 0.607 vs 0.462
- Defect density: 2.18x vs 0.56x
- ROC AUC: 0.731 vs 0.705
One pass, three signals you can read separately
Code health is not a single complexity number. repowise scores three co-equal views and keeps them apart on purpose, so a clean defect score never hides a performance-risk shape, and a maintainability smell never inflates the bug headline.
- Defect risk: the headline 1 to 10 score, weighted from a real defect corpus
- Maintainability: readability and change-cost smells that do not predict bugs
- Performance risk: static N+1 and IO-in-loop shapes, high precision by design (the findings it raises are real)
- All three are deterministic, no LLM, surfaced in get_health and PR reviews
From a score to a worklist
Health is only useful if it tells you what to do next. repowise ingests coverage, watches for decline, and ranks the fixes that buy you the most for the least effort.
- Coverage ingestion (LCOV, Cobertura) for untested-hotspot detection
- Declining-health and predicted-decline alerts
- Refactoring targets ranked by impact for effort, a worklist, not an auto-refactor
- Surfaced in get_health and in PR risk reviews
Deterministic, from index to score.
Index
repowise parses your repo into a graph and reads its git history. No code is sent anywhere.
Score
21 markers run with defect-calibrated weights, fully deterministic, in under 30 seconds on 3,000 files.
Validate
The bundled check shows whether the worst-scored files are the ones with recent bug fixes, on your repo.
Act
Refactoring targets ranked by impact for effort, plus alerts when any file's health slips.
One score, everywhere it helps.
In your AI agent
get_health and get_risk give agents the riskiest files and what to fix first, over MCP.
On every PR
The Repowise PR Bot comments when health regresses, deterministically, with zero LLM calls.
In the dashboard
KPIs, lowest-scoring files, and a module-level health rollup.
Over time
Health trends and declining-health alerts catch decay before it compounds.
For prioritization
Refactoring targets ranked by impact for effort, not gut feel.
For leaders
A defect-validated signal you can put in front of the board, tied to ownership and AI provenance.
Other tools publish a score. repowise publishes the score's predictive performance against real bug labels, head to head, and every heuristic is open source so you can reproduce it on your own repo.
Questions, answered
What does the code-health score actually measure?
Every file gets a single 1 to 10 score computed from 21 deterministic markers: McCabe complexity, deep nesting, brain methods, class cohesion (LCOM4), god classes, Rabin-Karp clone detection, change entropy, co-change scatter, ownership dispersion, prior-defect history, test-quality smells, and more. Lower scores mean the file is more likely to harbor defects.
How do you know the score actually predicts bugs?
It is defect-validated. On the same 2,770 files across 9 languages with real defect labels, ranking by repowise health surfaces 2.3x the defects of a leading commercial tool under the same review budget (recall 0.173 vs 0.074, effort-aware Popt 0.607 vs 0.462, ROC AUC 0.731 vs 0.705). Across 21 open-source repos the mean cross-project ROC AUC is 0.74 with a 95% confidence interval of 0.68 to 0.79, up to 0.90 on individual repos.
Does it use an LLM?
No. Scoring is fully deterministic: 21 markers with weights calibrated offline against a defect corpus. Only the learned constants ship, so the same code always produces the same score, in under 30 seconds on a 3,000-file repo. No cloud, no API calls, no drift.
How is this different from CodeScene?
Both score code health, but repowise is open source so every heuristic is inspectable and reproducible on your own repo, and the score ships inside a broader platform: an architecture-aware wiki, git intelligence, architectural decisions, agent provenance, and ten MCP tools for AI agents. repowise does not offer AI auto-refactoring.
Will it just flag big files?
No. The discrimination survives controlling for file size (partial Spearman rho of -0.16) and significantly out-discriminates both recent churn (+0.10 AUC) and prior-defect history (+0.12 AUC), with DeLong p below 1e-9.
Can it use my test coverage?
Yes. repowise ingests LCOV and Cobertura coverage to compute untested-hotspot risk (the intersection of low coverage and high hotspot score), alerts when a file's health starts declining, and ranks refactoring targets by impact for effort.
Can I prove these numbers on my own codebase?
Yes, that is the point. Every heuristic is open source under AGPL-3.0, and the validation runs on your own repo. On a typical project, 16 of the 20 lowest-health files had a bug fix in the last 6 months, 3.3x the 24% baseline.
Does repowise check performance?
Yes, as a static health pillar, not as an APM or profiler. repowise statically detects performance-risk shapes such as N+1 access and IO-in-loop patterns and scores them as a co-equal third pillar alongside defect risk and maintainability. It is high precision and low recall by design: it raises few findings, but the ones it raises are real. There is no runtime, no agent, and no tracing; it reads your source, like every other signal.
Does repowise refactor my code for me?
No, and that is deliberate. repowise ranks refactoring targets by impact for effort and alerts you when a file's health starts declining, but it hands you a human-readable, deterministic worklist; it does not open PRs or rewrite your code. The suggestions are template-based and inspectable, with no LLM editing your repo.
Last reviewed: June 2026
The complete code-health guide: the 21 biomarkers, the three pillars, and a walkthrough from score to fix.
The same signal, applied to a single commit or PR.
How much of your code AI wrote, and whether it is healthy.
Code health, ownership, and AI-debt for the people accountable.
Open-source, defect-validated code health, plus the wiki, decisions, and agent context CodeScene does not ship.
Reproducible defect validation and a full intelligence layer, open source and self-hostable, not just pass/fail quality gates.
Defect-validated, agent-native, and open source, with architectural decisions and a wiki beyond quality-gate dashboards.