repowise scores every file in your repo from 1 to 10 using 25 deterministic biomarkers, with no LLM and no cloud, reproducible byte-for-byte. The weights are calibrated against a real defect corpus, so the score reaches 0.74 cross-project ROC AUC across 21 repos and 9 languages and catches 2.3x more defects than a leading commercial tool at the same review budget. It runs in under 30 seconds on a 3,000-file repo and turns the score into a ranked worklist of what to fix first.
Code health is a per-file score from 1 (worst) to 10 (best) that estimates how likely a file is to harbor defects. repowise computes it from 25 deterministic biomarkers over tree-sitter ASTs and git history, with weights calibrated against a real defect corpus. It is reproducible: the same code always yields the same score, with zero LLM calls.

Why does code health matter?
Most code-quality tools hand you a score and ask you to trust it. None show whether the score actually finds the bugs.
A maintainability number is only useful if the files it flags are the files that break. Untracked, that gap costs real money: review time spent on the wrong files, regressions in code nobody flagged, and "tech debt" arguments with no evidence behind them.
- A score you cannot defend in review is a score the team ignores.
- The files that break are rarely the files that feel risky, so gut feel mis-ranks effort.
- Without calibration, a quality score measures what is easy to measure, not what predicts bugs.
How does code health work?
repowise treats "does this score find bugs?" as a measurable claim and publishes the answer. The mechanism is deterministic end to end.
1. Index. repowise parses your repo into a graph and reads its git history. No code is sent anywhere.
2. Score with 25 biomarkers. Each file starts at 10.0; biomarker findings deduct from the score, capped per category so no single category dominates.
| Category | Biomarkers |
|---|---|
| Structural complexity | brain_method, nested_complexity, bumpy_road, complex_conditional, complex_method, large_method, primitive_obsession |
| Cohesion & size | low_cohesion (LCOM4), god_class |
| Duplication | dry_violation (native Rabin-Karp clone detection) |
| Error handling | error_handling (empty catches, swallowed errors, bare panics) |
| Test coverage | untested_hotspot, coverage_gap, coverage_gradient |
| Test quality | large_assertion_block, duplicated_assertion_block |
| Organizational / git | developer_congestion, knowledge_loss, hidden_coupling, function_hotspot, code_age_volatility, ownership_risk, churn_risk, change_entropy, co_change_scatter, prior_defect |
| Performance | io_in_loop (N+1), string_concat_in_loop, blocking_sync_in_async, resource_construction_in_loop, serial_await_in_loop, and more |
3. Calibrate, don't hand-tune. Each file is scored at the commit before a 6-month defect window (T0, so the measurement cannot leak the future). An L2-regularized logistic regression with file size (NLOC) as an explicit control fits each biomarker's defect lift beyond size. The strongest calibrated predictors: co_change_scatter, change_entropy, ownership_risk, nested_complexity. Only the learned constants ship.
4. Split into three co-equal signals. One shared scoring kernel runs against three independent weight/cap tables. They never feed back into each other; the surfaced score stays exactly the defect score (a golden test locks this byte-for-byte).
| Pillar | What it scores |
|---|---|
| Defect risk | The headline 1-10 number, calibrated against the defect corpus (Alert files carry roughly 17x the defect rate of Healthy files). |
| Maintainability | Smells the defect calibration floors (low_cohesion, brain_method, primitive_obsession, dry_violation, error_handling) scored at full weight where they actually live. |
| Performance risk | Static N+1 / IO-in-loop shapes that waste work: high-precision, low-recall, always advisory. |
How does code health help you?
The score is the start. repowise turns it into something you act on the same day.
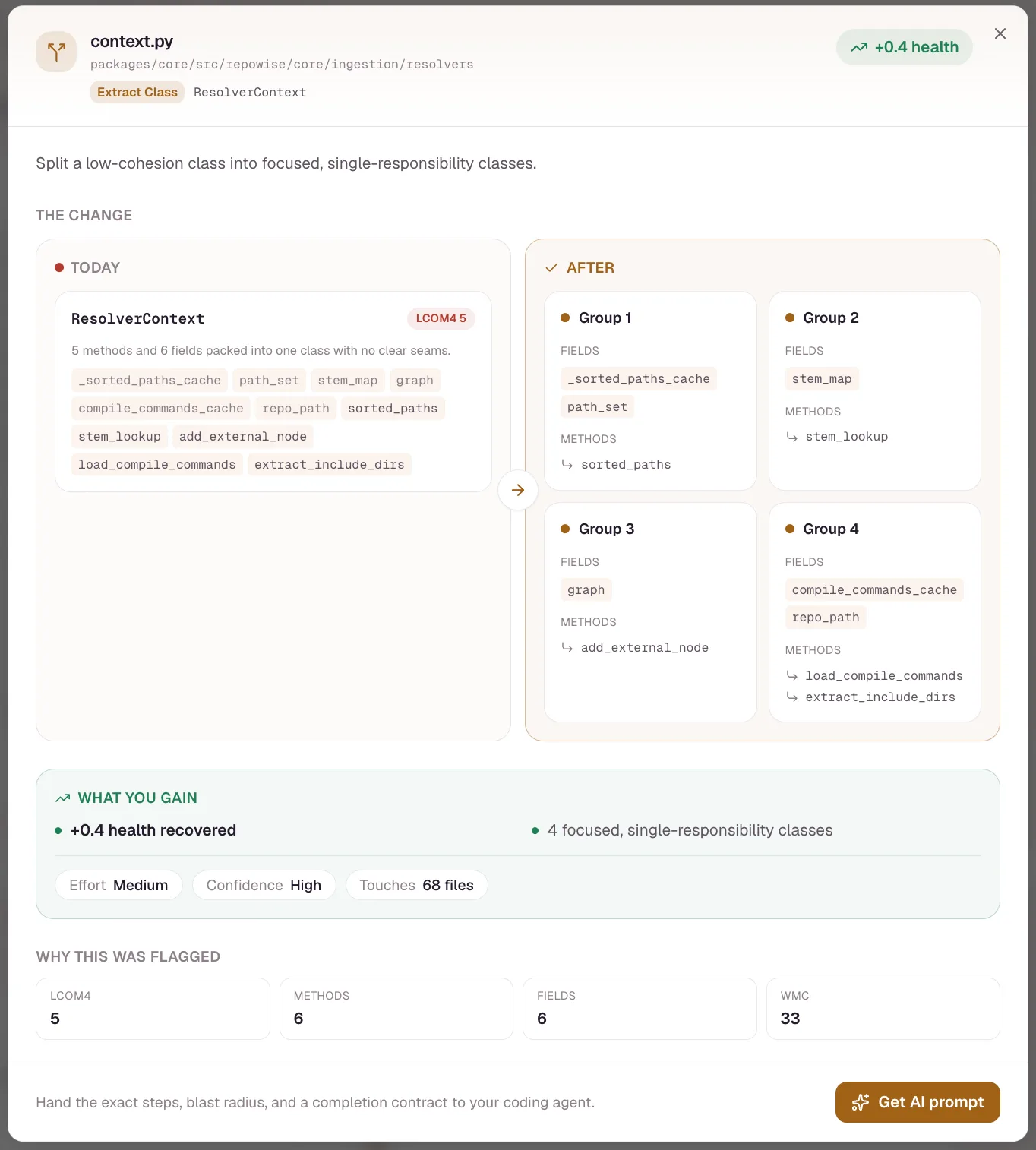
Refactoring prioritization
repowise ranks the files worth fixing by impact for effort, so you spend a refactoring budget where it pays back most.
Guardrail: this is a worklist, not an auto-refactor — repowise ranks and explains, it never rewrites your code.
- Each target carries a
score, the drivingbiomarker, animpactestimate, and an effort bucket (S/M/L/XL). - Ranking is deterministic and rule-based, with no LLM, so the worklist is reproducible across runs.
- High-impact / low-effort targets float to the top; you can mark findings
acknowledged,resolved, orfalse_positive.
Performance risk
The third pillar flags code whose structure does redundant I/O, not measured runtime.
Guardrail: this is a static performance-risk pillar, not an APM or profiler — no runtime, no traces.
- The headline detector is
io_in_loop(the N+1): adb/network/filesystem/subprocesscall that runs once per loop iteration, resolved through a shared I/O-boundary classifier so it only fires on a real round-trip. - A bounded-depth (≤3 hops) call-graph walk catches the interprocedural case no file-local linter sees; cross-function findings carry the resolved
caller → … → sinkpath. - Hand-label validated across an 11-repo OSS corpus: Go 96.7%, TypeScript 100%, Python 96.2% precision. A language without a dialect emits no perf findings, never a wrong one.
Coverage to untested hotspots
Point repowise at an LCOV or Cobertura file and it intersects coverage with churn-complexity to find the files that are both risky and untested.
Guardrail: coverage here is an input that sharpens risk, not a coverage dashboard.
repowise health --coverage cov.lcovlights upuntested_hotspot,coverage_gap, andcoverage_gradientbiomarkers.- Accepts LCOV, Cobertura, Clover, or normalized JSON.
- The output is "fix these untested risky files," not a wall of per-line coverage percentages.

Dead code
Before a cleanup sprint, repowise surfaces unreachable files, unused exports, and zombie packages, tiered by confidence.
- Findings tier high (≥0.8) / medium / low, with per-directory and per-owner rollups.
safe_onlyreturns deletion-ready findings with no runtime-load risk.- Available over MCP via
get_dead_codeand in the dashboard.
Trends and decline alerts
A rolling 50-row snapshot history powers Declining Health and Predicted Decline alerts, so decay surfaces before it compounds.
repowise health --trendshows snapshots plus declining and predicted-decline alerts.- The Repowise PR Bot comments deterministically when health regresses, with zero LLM calls.
- Trend data is surfaced in
get_healthand on the dashboard.
Walkthrough: from score to fix
Step 1 — Read the dashboard. Open code health and read the three KPIs: Hotspot Health (NLOC-weighted over hotspot files), Average Health (all files), and Worst Performer (the single lowest file).
Step 2 — Open a low-scoring file. Click into a file to see its biomarker findings, each tagged with a dimension (defect / maintainability / performance) so you can filter by pillar.
Step 3 — Check the worklist. Switch to refactoring targets, sorted by impact for effort. Pick the highest-impact S or M rows first.
Step 4 — Add coverage. Run repowise health --coverage cov.lcov to surface untested hotspots and re-rank with test gaps factored in.
Step 5 — Watch the trend. Run repowise health --trend (or let the PR bot do it) so any file's decline raises an alert before it ships.
Proof: does the score predict real bugs?
Every claim below is reproducible on your own repo: the heuristics are open source under AGPL-3.0.
| Result | Value |
|---|---|
| Cross-project mean ROC AUC | 0.74 [95% CI 0.68-0.79], up to 0.90 per repo |
| Defects caught vs a leading commercial tool, equal budget | 2.3x (recall 0.173 vs 0.074, Popt 0.607 vs 0.462) |
| Head-to-head discrimination (ROC AUC) | 0.731 vs 0.705, on the same 2,770 files / 9 languages |
| Survives controlling for file size | partial Spearman ρ = −0.16 |
| Beats recent-churn baseline | +0.10 AUC (DeLong p < 1e-9) |
| Beats prior-defect baseline | +0.12 AUC |
| External, never-seen dataset (PROMISE/jEdit) | AUC 0.76-0.78 |
| Biomarkers | 25, deterministic, zero LLM, reproducible |
| Speed | < 30s on a 3,000-file repo |
Full methodology and reproduction steps live in the defect-prediction validation study.
Try it on your repo
See whether the score finds the bugs in your repo: every heuristic is open source and runs locally.
pip install repowise
repowise health # KPIs + lowest-scoring files
repowise health --coverage cov.lcov # untested-hotspot detection
repowise health --refactoring-targets # ranked by impact / effort
repowise health --trend # snapshots + decline alertsHow each role uses this feature
Filter findings by the defect dimension, take the top S/M refactoring target, and self-check before a PR with get_health(include=["accuracy"]).
Put a defect-validated signal in front of the board, tied to ownership and AI provenance rather than gut feel.
Set .repowise/health-rules.json policy (per-glob biomarker toggles, the small-team profile) while the calibrated weights stay locked.