AI writes half your code. Trust it anyway.
repowise shows how much of your codebase AI agents wrote, whether it is healthy, and who actually owns it, from your git history alone. No IDE plugins, no developer surveillance. The one view nobody else has: which AI-written code is also a low-health hotspot owned by a single person.
AI now writes a large and growing share of your code, that code carries more defects, and you are accountable for all of it, but you cannot see where it is or who would have to fix it.
Industry data puts AI at roughly 42% of code in 2026, with about 1.7x more issues than human-written code and rework rising sharply past a 40% AI share. Code-quality tools score the debt but are blind to who wrote it. Eng-metrics platforms see authorship but need org-wide IDE instrumentation and a six-figure contract. repowise reads the history you already have and ties health to ownership and to the agents that wrote the code.
A radar for the risk AI is adding to your codebase.
repowise indexes your repos once and fuses provenance, code health, and ownership into one picture, all deterministic and computed from git history, so the answer is reproducible on your own repo.
See your true AI-code footprint
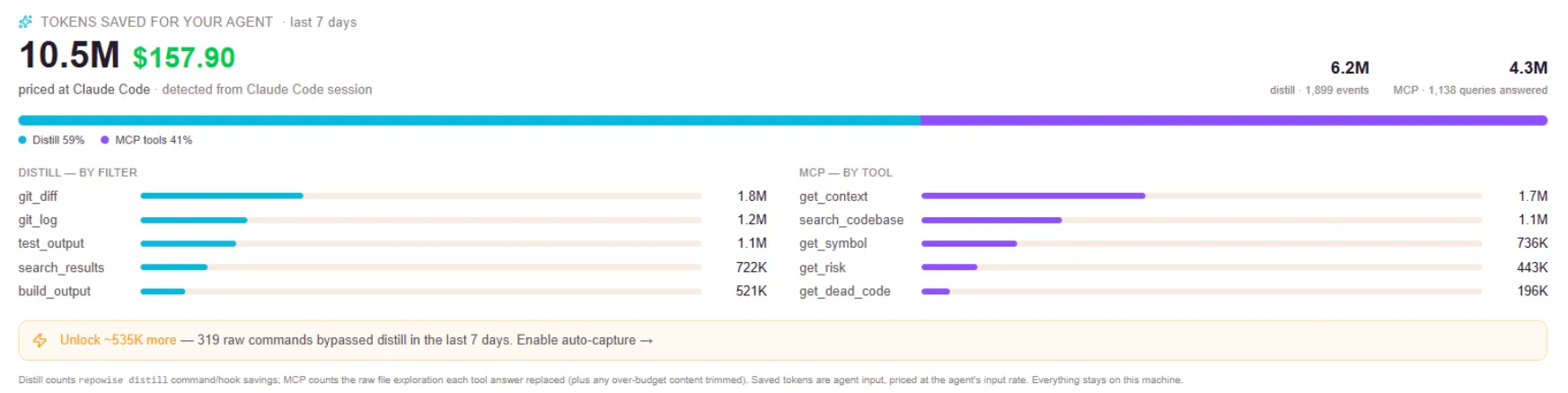
repowise attributes commits to the coding agents that produced them and rolls that up into an AI-code footprint across files, modules, and the whole codebase. It is computed from your existing git history, with no IDE plugins and no developer instrumentation, because traditional author fields miss a large share of AI contributions. Read it as a directional risk signal about where AI-written code is concentrated, not a per-developer productivity ledger.
- Commit attribution to agents, from the history you already have
- Footprint rolled up per file, per module, and across the repo
- No IDE plugins, no keystroke logging, no surveillance
- Works retroactively on your whole history, not just going forward
The fusion nobody else has
Across the competitive landscape, nobody combines these three signals on one surface: which AI-written code is also a low-health hotspot owned by a single person. That intersection is where AI debt actually bites, and it is exactly what you need to govern. This is risk management for AI-era codebases, framed deliberately as risk and ownership, never as developer-productivity scoring.
- AI authorship crossed with the defect-validated health score
- Hotspots that are also bus-factor-of-one, surfaced first
- Direct review effort to where the risk concentrates
- Reproducible on your own repo, every heuristic open and inspectable
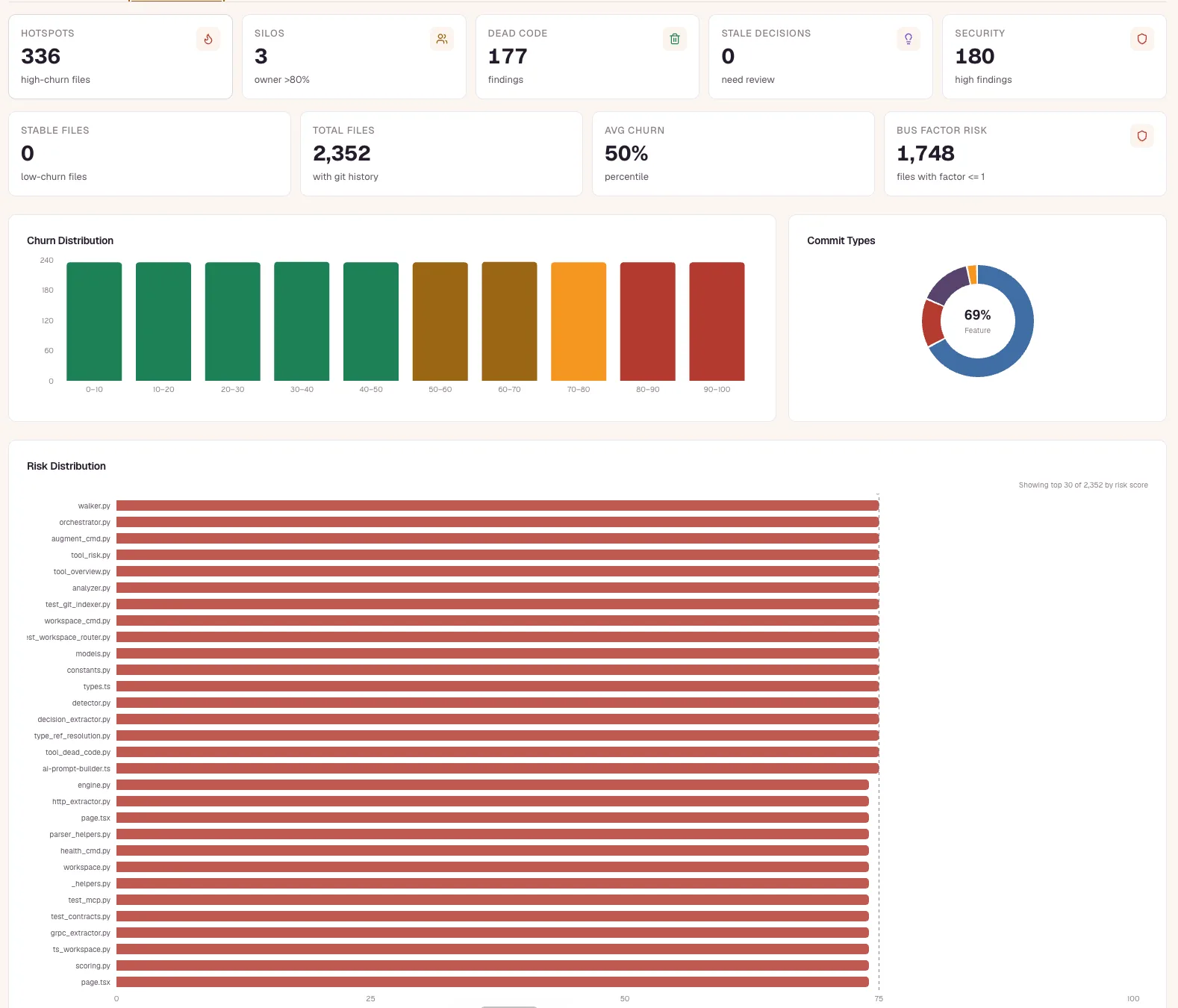
A health score proven to predict real bugs
repowise scores every file 1 to 10 from 21 deterministic markers, including McCabe complexity, deep nesting, brain methods, class cohesion, clone detection, untested hotspots, ownership dispersion, change entropy, and co-change scatter. Weights are calibrated offline against a defect corpus, so the runtime stays deterministic with no LLM in the loop and the same code always scores the same.
- Cross-project ROC AUC 0.74 (95% CI 0.68 to 0.79), up to 0.90
- 2.3x defects under fixed review budget, recall 0.173 vs 0.074
- The same pass scores maintainability and static performance risk as separate pillars, and intersects coverage with churn-complexity to surface the untested hotspots your test budget should target first.
- A churn x complexity maintainability map pinpoints the volatile-and-complex files, with a static performance-risk pillar, not an APM or profiler, and coverage as an input that sharpens risk, not a dashboard
- Trends over time with declining-health alerts
- 21 deterministic markers, under 30 seconds on 3,000 files
Key-person risk before someone leaves
repowise surfaces ownership concentration across the codebase from git history: files owned more than 80% by a single author, knowledge silos, and the bus-factor-of-one modules that would stall if one person left. You see where tribal knowledge is dangerously concentrated while you can still do something about it, not in the exit interview.
- Ownership percentage per file and per module
- Bus-factor-of-one modules flagged across the repo
- Knowledge silos and ownership dispersion surfaced from history
- Pairs with provenance and health to rank what to de-risk first

From your git history to a risk picture in four steps.
Index your repos
repowise builds the graph, git, and code-health layers from your existing history. No IDE plugins, no telemetry, deterministic and reproducible.
See your AI-code footprint
Provenance attributes commits to the agents that wrote them, rolled up across files, modules, and the whole codebase.
Spot the risky concentrations
The AI-debt radar surfaces AI-written code that is also a low-health hotspot owned by a single person.
Act before it bites
Direct review effort, add tests, and spread ownership where the risk concentrates, with declining-health alerts as it shifts.
Governance and risk, grounded in your real codebase.
Board and stakeholder reporting
Defect-validated code health and trends give you a credible, reproducible read on engineering risk instead of vibes. The leader dashboard that rolls this up across repos ships today on the Teams tier.
Onboarding risk
See which modules are low-health and thinly owned before you point new engineers or new AI agents at them.
Offboarding and bus factor
Find bus-factor-of-one modules and knowledge silos before a key person leaves and the context goes with them.
AI governance
Quantify your AI-code footprint and watch where AI-written code concentrates risk, as risk management rather than developer scoring.
Portfolio health across repos
Compare health and AI-debt across services to decide where to invest. The portfolio health dashboard is live today on the Teams tier.
Where to invest review effort
The AI-debt radar ranks the intersections of AI authorship, low health, and concentrated ownership so review time goes where it pays off.
Code-quality tools score your debt but are blind to git history and AI authorship. Eng-metrics platforms see authorship but need org-wide IDE instrumentation and six-figure contracts. repowise reads the history you already have, ties health to ownership and to the agents that wrote the code, and is open source and self-hostable so you can reproduce every number on your own repo.
Questions, answered
How do you measure how much code AI wrote?
repowise reads your existing git history and attributes commits to the coding agents that produced them, then aggregates that into an AI-code footprint across files, modules, and the whole repo. It is computed from the history you already have, with no IDE plugins and no developer instrumentation. Traditional git metadata misses a large share of AI contributions, so repowise reads the shape of the work rather than trusting author fields alone. Treat the result as a directional risk signal about where AI-written code is concentrated, not a precise per-developer productivity ledger.
Is this developer surveillance?
No. repowise is built for risk management, not productivity scoring. It answers where AI-written code lives, whether that code is healthy, and whether ownership is dangerously concentrated, so you can direct review effort and reduce key-person risk. It does not rank engineers, time keystrokes, or grade output. The whole approach reads git history that already exists rather than instrumenting people, which is a deliberate choice: the productivity-surveillance framing is baggage we stay clear of on purpose.
How accurate is the code-health score?
The code-health score is defect-validated. Across 21 open-source repositories in 9 languages, it reached a mean cross-project ROC AUC of 0.74 (95% CI 0.68 to 0.79), up to 0.90 on individual repos, and it survives controlling for file size. In a head-to-head against a leading commercial tool on the same 2,770 files, ranking by repowise health surfaced 2.3x the defects under a fixed review budget, with recall 0.173 versus 0.074. The score is 21 deterministic markers with no LLM in the loop, so the same code always produces the same score.
Does it work retroactively on our history?
Yes. repowise builds its graph, git, and code-health layers from your existing repository, so the AI-code footprint, ownership, bus factor, and health trends are derived from history you already have. You do not need to instrument anything going forward to see where you stand today. This is a deliberate contrast with tooling that only attributes code from the moment you install it.
How is this different from CodeScene or GitClear?
CodeScene has code health and bus factor but no AI provenance. GitClear owns the AI-code-quality research narrative but reports aggregate industry trends, not per-agent attribution of your own code tied to health and ownership. repowise fuses three signals on one surface that nobody else combines: which AI-written code is also a low-health hotspot owned by a single person. It bundles that with an auto-wiki, a dependency graph, and architectural decisions, it is open source and reproducible on your own repo, and the health score is defect-validated head-to-head. We do not claim CodeScene's peer-reviewed research moat or auto-refactoring, and we are complementary to DORA and flow platforms rather than a replacement for them.
Can we self-host it?
Yes. The core engine is open source under AGPL-3.0 and runs entirely on your own infrastructure. Your source code is processed transiently and never persisted, with zero telemetry, and you can bring your own API key or run fully offline via Ollama. A commercial license is available to remove the AGPL obligation; SSO and SCIM for identity are still rolling out on the enterprise track. The leader dashboard, portfolio health across repos, and owner/admin/member roles are shipped today on the hosted Teams tier.
Do you need IDE plugins or agent instrumentation?
No. Provenance, ownership, bus factor, and code health are all derived from your git history. There is nothing for engineers to install in their editor and nothing logging their activity. That is what makes the AI-debt radar a repo-side risk signal rather than an org-wide instrumentation project with a six-figure contract attached.
What does the engineering-leader dashboard cover, and is it shipped?
It is shipped, as part of the Teams tier. The leader dashboard rolls up engineering signals across every team repo: nightly drift detection for hotspot drift, bus-factor risk, health decline, and decision staleness, with trends, recent alerts, and a weekly digest. It sits alongside the portfolio health dashboard, ownership and bus-factor intelligence, and owner/admin/member roles, all live today. See the Teams page at repowise.dev/for/teams or the pricing page for what the tier includes. SSO and SCIM provisioning remain on the enterprise roadmap, and we do not present those as shipped.
Last reviewed: June 2026
Your AI-code footprint, attributed from git history, no IDE plugins.
The defect-validated 1 to 10 score behind the radar (ROC AUC 0.74).
Ownership, bus factor, hotspots, and hidden coupling from history.
The leader dashboard, portfolio health, and roles ship in the Teams tier.
See how much of your code AI wrote, tied to health and ownership, not just industry trends.