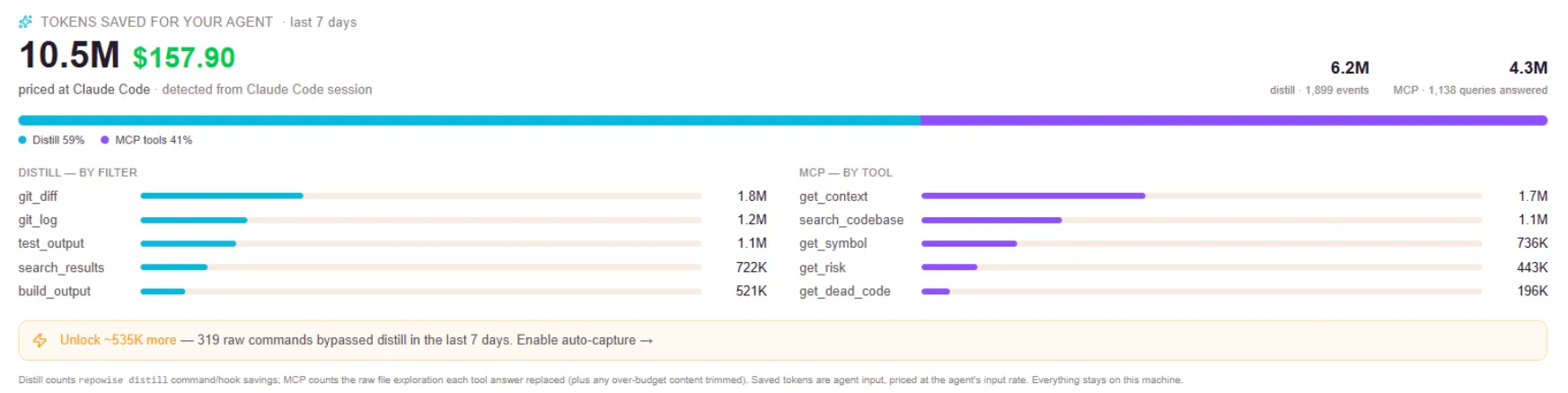
repowise reads your git history alone to attribute commits to the AI agents that wrote them, then fuses that authorship with the defect-validated 1-to-10 health score and bus-factor ownership. That intersection is the AI-debt radar: AI-written code that is also a low-health hotspot owned by a single person, ranked. It needs no IDE plugins and works retroactively on the code AI already wrote.
Agent provenance is repowise attributing each commit to the AI agent that produced it, computed deterministically from git history rather than IDE instrumentation. Fused with the defect-validated health score and bus-factor ownership, it forms the AI-debt radar: a ranking of AI-written code that is also low-health and single-owner, the actual risk surface rather than a raw AI percentage.
Why does agent provenance matter?
A growing share of your codebase is now written by AI agents, and almost no one can tell you which code that is. Knowing your repo is 40-something percent AI-written is a headline, not a plan.
Industry-wide, roughly 42% of code is AI-written in 2026, and surveys report roughly 1.7x more issues in AI-generated code than human code. But a raw percentage cannot tell you where to look, and a survey cannot tell you which file will break.
- A percentage is a vanity metric: it ranks nothing and directs no review.
- AI agents do not carry the context a long-tenured engineer would, so their code lands without the same shared familiarity.
- When AI code lands in a low-health file owned by one person, the usual safety nets, review familiarity and shared ownership, are thinnest exactly where the risk is highest.
How does the AI-debt radar work?
repowise treats AI authorship as a signal to fuse, not a number to display. The mechanism is deterministic end to end, computed from the git log you already have.
1. Index. repowise parses your repo into a graph and reads its git history. No code is sent anywhere and nothing is installed on developer machines.
2. Attribute by agent. A per-commit provenance detector reads eight signals from history alone, then validates with no model in the loop.
| Signal class | What it reads |
|---|---|
| Account identity | Bot account identities and service email addresses |
| Commit metadata | Commit-message footers and co-author trailers |
| Merged-PR evidence | Agent branch prefixes and PR-body markers |
| Confidence handling | A human follow-up commit inside an agent's PR is downgraded so it can be filtered |
Blind-validated across 124 commits by six independent reviewers, the detector returned 96.2% precision, with six of the eight channels perfect.
3. Fuse three signals. AI authorship on its own is a vanity metric; the radar intersects it with two signals already in repowise.
| Signal | What it contributes |
|---|---|
| AI authorship | Which commits, and which resulting code, an agent produced |
| Code health | The defect-validated 1-to-10 score (cross-project ROC AUC 0.74), so low-health files surface |
| Bus-factor ownership | Files owned more than 80% by one author, flagged from git blame |
4. Rank the radar. The intersection, AI-written and low-health and single-owner, is the actual risk surface. repowise ranks it so leaders and reviewers know where to look first.
This is a directional risk lens on files and agents, not a per-developer productivity ledger. It reads commits; it does not watch people.
How does it help you?
The radar turns a statistic into something a team can act on the same day, and it lands everywhere the work happens.
A risk surface, not a percentage
Provenance fused with health and ownership ranks the AI code most likely to cause an incident.
- AI-written, low-health, and single-owner files are ranked together, highest risk first.
- Tied to the same 25-biomarker score that surfaces 2.3x the defects under a fixed review budget.
- The output is "review these files first," not "your repo is X% AI."
Surfaced where you already work
An AI-authorship flag is never an island; it sits on the same surface as the rest of repowise.
- In your AI agent:
get_risksurfaces AI-authored hotspots and what to check first, over MCP, alongside health and ownership. - On every PR: the Repowise PR Bot can flag deterministically when AI-written code lands in a low-health, single-owner file.
- In the dashboard: your AI-code footprint per module, ranked by the radar rather than raw percentage.
Grounded in the data, not the hype
The radar exists because the real risk is concentration, not a wave of extra bugs.
Guardrail: this is a directional risk signal, not a per-developer ledger — it reads commits, it does not watch people.
- Across 112,382 commits in 28 repos, agent commits were no more bug-inducing than human commits in the same repo.
- Human-driven agents, where a person is still reviewing the diff, came in at an odds ratio of 0.57 [95% CI 0.42-0.76], and agent lines outlived human lines by 17.9 percentage points.
- So the radar targets the dangerous intersection, AI code in a low-health, single-owner file, rather than treating all AI code as suspect.
Walkthrough: from commit to AI-debt view
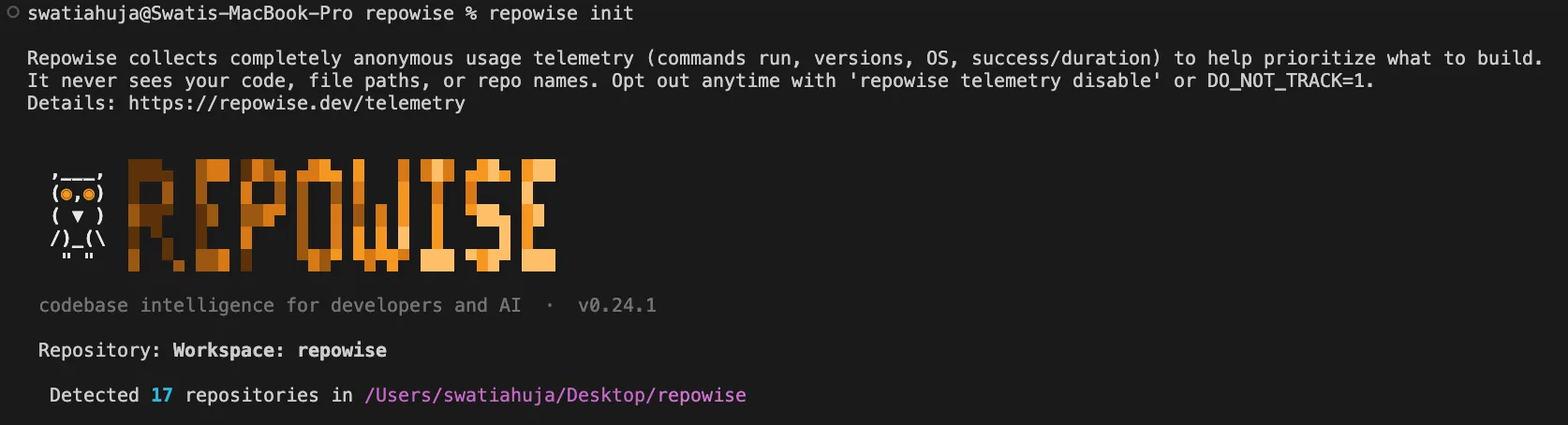
Step 1 — Index your repos. Run repowise init to build the graph, git history, and health from your existing history. No IDE plugins, no telemetry.
Step 2 — Read the AI-code footprint. Provenance rolls up per file, module, and repo, so you see how much AI wrote before any fusion.
Step 3 — Open the AI-debt radar. Switch to the radar to see AI-written, low-health, single-owner files ranked together, highest risk first.
Step 4 — Act. Direct review and tests at the top of the radar, spread single-owner files, and let declining-health alerts track the shift over time.
Proof: what the radar stands on
Each result below is reproducible: the health heuristics are open source under AGPL-3.0, and the provenance study ships its analysis scripts.
| Result | Value |
|---|---|
| Provenance precision (blind-validated, 124 commits, 6 reviewers) | 96.2%, six of eight channels perfect |
| Provenance signals read from history | 8 (identities, emails, footers, trailers, PR markers) |
| Study behind the radar | 112,382 commits across 28 repos |
| AI vs human bug induction (same repo) | Agent commits no more bug-inducing; human-driven tier OR 0.57 [0.42-0.76] |
| Agent line survival vs human | +17.9 percentage points longer-lived |
| Health score the radar fuses with | Cross-project ROC AUC 0.74, up to 0.90 per repo |
| Bus-factor flag | Files owned more than 80% by one author |
| Instrumentation required | 0 IDE plugins, retroactive on existing history |
The full provenance study, per-repo numbers, and analysis scripts are open in the is-AI-code-buggier study; the health score it fuses with is documented in the defect-prediction validation study.
How each role uses this feature
Get a board-ready read on how much of the codebase AI wrote and whether it is healthy, tied to a defect-validated score and ownership rather than a raw percentage. Open the AI-debt radar to see AI-written, low-health, single-owner files ranked, and direct review and tests there first.
Before you extend or trust AI-authored code, get_risk surfaces whether a file is AI-written and also a low-health hotspot, alongside its dependents and owner. Check the radar so the AI code you build on is not the code most likely to break.