Is AI-written code buggier than human code? We blamed 112,000 commits to find out
Ask ten engineers whether AI-written code is buggier than the code they write by hand and you'll get ten confident answers, roughly half in each direction, and zero of them backed by a number. It's one of those questions where everyone has a prior and nobody has the data. The takes are loud, the measurements are scarce, and the few measurements that exist tend to be a survey of how people feel about AI code rather than what the code actually does once it's merged.
So we measured it the way the defect-prediction field measures everything else: by going back through the git history of real projects and blaming every bug fix to the commit that introduced the bug. We did this across 28 public repositories and 112,382 commits spanning the first year of coding agents merging real pull requests, and then we asked a simple question of the data. When an agent wrote the commit, was it more likely to be the one that planted a bug than a human commit in the same codebase?
The short version: no. If anything, the opposite. And the agent-written lines that did land stuck around longer than the human-written ones. The longer version, with the caveats that make me actually believe it, is the rest of this post.
What "agent code" even means
The first problem with this question is that "AI wrote it" isn't one thing. A senior engineer driving Claude Code through a careful refactor and an unattended bot opening PRs on a schedule are both "AI code," and lumping them together would hide whatever signal exists. So before measuring anything we built a per-commit provenance detector that reads eight different signals: bot account identities, service email addresses, commit-message footers, co-author trailers, and merged-PR evidence like agent branch prefixes and PR-body markers. We then blind-validated it, handing 124 commits to six independent reviewers, and it came back at 96.2% precision, with six of the eight detection channels perfect. The one real failure mode, a human pushing a follow-up commit inside an agent's PR, gets its confidence downgraded so we can filter it.
With provenance in hand we split agent commits into three tiers and, importantly, never pooled them:
- T1, bot agents. Near-autonomous, no human in the immediate loop. Think Devin, the Copilot coding agent, Cursor's cloud agents.
- T2, human-driven agents. Claude Code, Codex, and friends, where a developer is steering and reviewing as they go. This is the overwhelming majority of agent commits in the wild.
- T3, AI-assisted. A co-author trailer and not much else, the lightest touch.
That tiering turns out to matter, because the tiers behave differently, and any honest version of this story has to keep them apart.
How you measure "this commit caused a bug"
The standard tool here is SZZ, named after Śliwerski, Zimmermann and Zeller. The idea is mechanical: find the commits that fix bugs, then git blame the lines they changed to find the commit that last touched those lines, and call that earlier commit the one that introduced the bug. Do this across a whole repo and you get a labeled dataset of bug-inducing and not-bug-inducing commits.
We ran SZZ within each repository, comparing agent commits to human commits in the same codebase, which controls for the obvious confound that some projects are just buggier than others. Then we fit a logistic model with the lines added, lines deleted, and files touched as controls, plus a repo fixed effect, so that every result reads as "bug risk beyond what the size of the change already explains." That size control is not optional. The single strongest predictor of whether a commit introduces a bug is how big the commit is, and if you skip the control you mostly end up measuring whether agents write bigger or smaller diffs than humans.
There's one more piece of discipline that ended up being the difference between a believable result and a flattering one. Naive SZZ has a built-in bias in favor of agents here. It excludes fix commits from being counted as bug-inducers, and agents do a disproportionate amount of fixing, so the naive method quietly shields them. To catch that, we ran a stricter variant (B-SZZ) as a mandatory sensitivity check on every single result. If a finding only shows up under the friendly variant and evaporates under the strict one, it isn't real. I'll tell you below exactly where that line falls.
The headline: agent commits are not more bug-inducing
Here is the core result, the adjusted odds of a commit introducing a bug, by authorship tier, relative to human commits in the same repo. Below 1.0 means fewer bugs than the human baseline.
 Adjusted odds of introducing a bug by authorship tier, controlled for change size and churn
Adjusted odds of introducing a bug by authorship tier, controlled for change size and churn
Every tier lands at or below the human line. Human-driven agents (T2) come in at an odds ratio of 0.57, with a 95% confidence interval of 0.42 to 0.76, so the whole interval sits below 1.0. Bot agents (T1) are at 0.75 [0.43, 0.95]. The lightest-touch assisted tier (T3) is at 0.96 [0.69, 1.08], which is just indistinguishable from human, exactly what you'd expect from commits that are mostly human-authored anyway.
Now the honesty pass. Under the strict B-SZZ variant, the T2 effect attenuates toward the null: it moves to 0.79 with an interval of [0.68, 1.01] that just barely touches 1.0. So I would not stand behind the strong claim that agents are "43% less bug-prone." What I will stand behind, because it holds across every variant and every tier we tested, is the weaker and more durable claim: there is no evidence that agent commits introduce more bugs than human commits in the same repo, and the point estimates are consistently protective, never worse. The thing the loud half of the internet is sure about, that AI is shipping a wave of extra bugs, is not visible in the blame graph.
The lines also last longer
Bug induction is one lens. Another is durability: when an agent writes a line of code, does it survive in the codebase, or does it get ripped out and rewritten a month later? "Agent code all gets thrown away anyway" is a common deflection even from people who accept the bug numbers, so we measured that too.
We sampled files across the repos, took the lines added six or more months before the current HEAD, and computed what fraction were still present, paired within each repo so we're comparing agent and human lines from the same project and the same era.
 Line survival to HEAD, human versus human-driven agent, paired within repo
Line survival to HEAD, human versus human-driven agent, paired within repo
In every repo with enough human-driven-agent volume to measure, the agent lines survived at a higher rate than the human lines, by 17.9 percentage points in aggregate, with a confidence interval well clear of zero. The slopes all tilt the same way. The one exception anywhere in the study was a single bot-agent (T1) deployment in one repo that re-fixes its own files about three times as often as the others, and unsurprisingly its lines churn out faster. Deployment pattern, again, beats the agent's brand name.
Why might this be true?
A result this counter to the vibe deserves a mechanism, and I think there are three honest ones.
The first is selection by review. These are merged commits, which means they already cleared whatever review bar the project enforces. It is entirely plausible that agent PRs get scrutinized harder than a trusted human teammate's, and that some of the protective effect is really measuring reviewer stringency rather than the model's raw output. I'll come back to this, because it's the caveat I take most seriously.
The second is that agents are disproportionately the maintenance crew. When we characterized what agent commits actually do, they skew heavily toward fixes rather than net-new features. Fix-shaped commits, small, localized, touching code that already exists and works, are simply lower-risk than greenfield feature commits, and a lot of agent volume is exactly that shape.
The third is the boring one that's probably underrated: a lot of human commits are also not very good. The human baseline is not a senior engineer at their best; it's the realistic mix of rushed Fridays, unfamiliar subsystems, and "just ship it" that any real repo contains. An agent that is merely consistent can clear that bar.
The caveats I'd raise before anyone over-reads this
I want these louder than the headline, because a study like this is only as trustworthy as the things it refuses to claim.
- These are reviewed, merged commits. The result says nothing about unreviewed agent output dumped straight to a branch, and some of the protective effect is likely review stringency, not the model.
- We can only see detected agent code. A developer who pastes an agent's output and commits it under their own name with no marker is invisible to us and counts as "human." Every agent number here is therefore a floor, not a ceiling.
- Agent-heavy repos are young. The agent era is about twelve months deep. That's why every comparison is within-repo or against matched controls, never a raw pooled rate, and why we owe a re-run in six months when the windows double.
- The corpus is not a random sample. It skews toward projects that keep attribution and toward AI-adjacent tooling. We deliberately oversampled boring non-AI projects (a 17-year-old Java framework, a CMS, observability and chat platforms) as counterweight, but we're not claiming population-wide rates.
- SZZ is SZZ. Blame-based induction inherits the method's known limits with tangled commits and large refactors, which we guard against but cannot fully eliminate. That's the whole reason the strict B-SZZ variant rides along with every number.
A bonus finding for the defect-prediction crowd
One thing fell out of this work that's worth its own mention, because it bit us before we understood it. In repos where agents write most of the commits, the cheap way everyone labels bugs, keyword and file-level "this file was touched by a fix" heuristics, falls apart. The fix firehose is so constant that in the most extreme repo, 86% of files counted as "buggy," which drags any predictor's accuracy down toward a coin flip. For a while that looked like "agent repos break defect prediction."
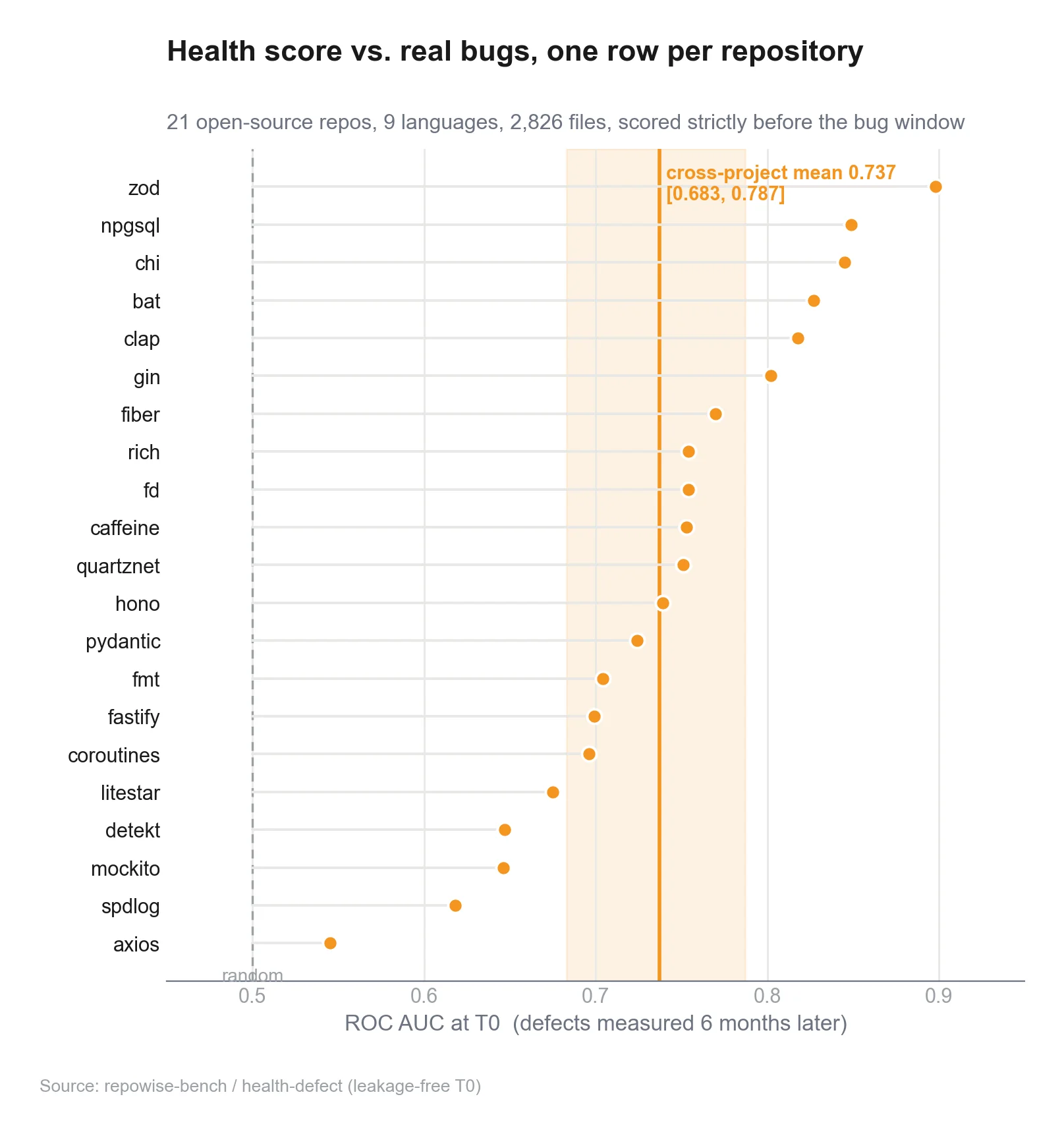
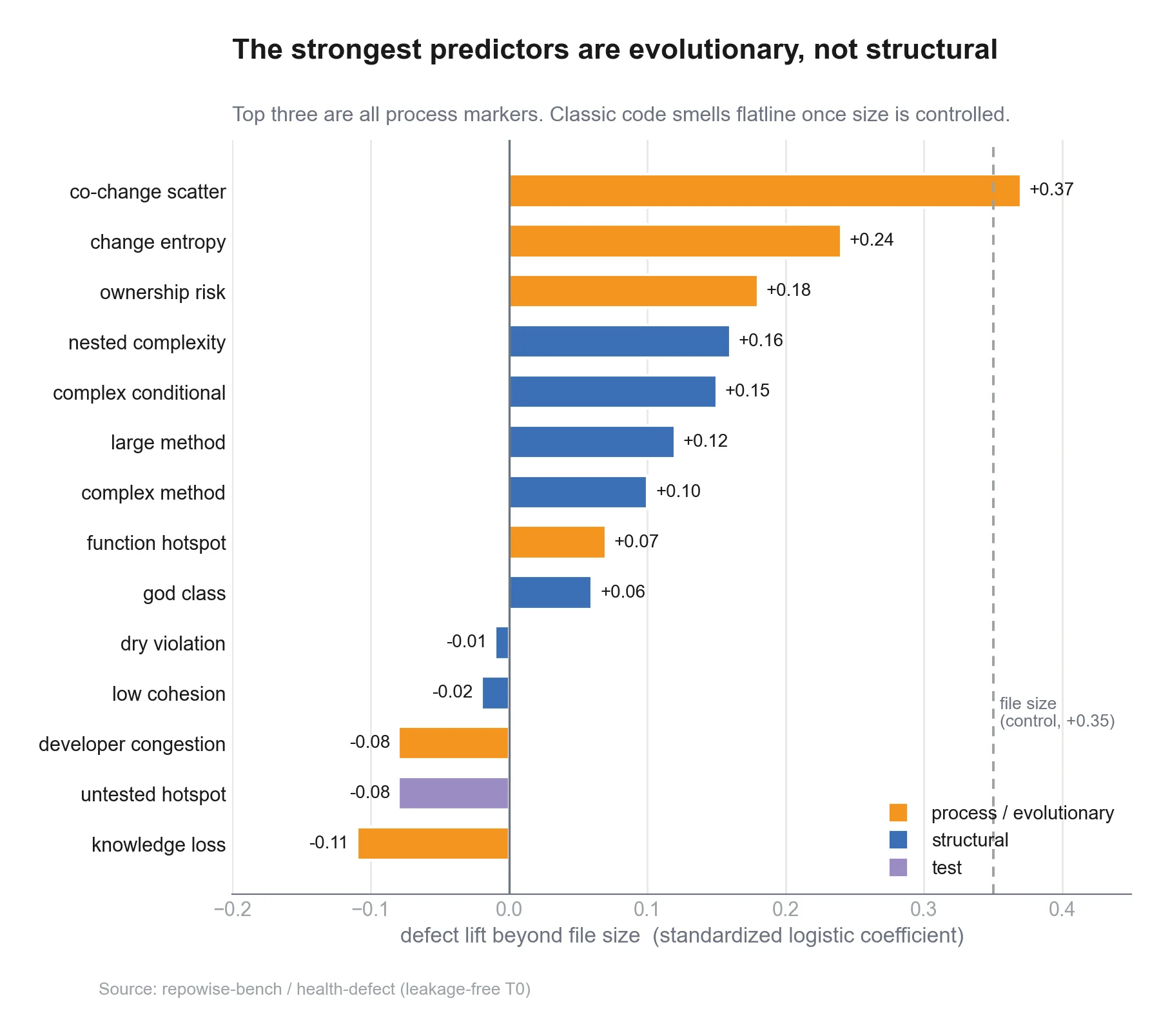
It isn't, quite. What breaks is the labeling shortcut, not the underlying structure. When we moved to commit-level SZZ labels and de-spammed the obvious self-fix churn, prediction came right back; the usual signals (prior fixes, churn, ownership) work fine on agent code. It's a measurement problem masquerading as a modeling problem, which is a distinction we care about a lot, since the whole Repowise code-health score is built on getting that kind of labeling right. If you want the deeper version of how we keep these history-based signals honest, the companion posts on why process metrics beat structural metrics and whether our health score actually predicts bugs both go into the leakage traps in detail.
So, should you trust the robot?
If you came for a verdict: the fear that AI agents are flooding codebases with bugs is not supported by the blame history of 28 real projects. Across 112,382 commits, agent commits were no more likely to introduce a defect than human commits in the same repo, the point estimates leaned protective, and agent-written lines outlived human ones. The effect is real but modest, and it lives almost entirely in the human-driven tier, the one where a person is still reviewing the diff. That last part is not a footnote. The story the data tells isn't "the robots are better," it's "a competent human plus an agent, with the human still reading the code, produces commits that hold up at least as well as that human working alone." Which, honestly, is the workflow most of us are already in.
The full report, the per-repo numbers, the strict-variant sensitivity tables, and every analysis script (so you can re-run it on your own corpus) are open in the Repowise benchmark repo. And if you want to see the same history-based health signals computed live on a real codebase, the public repo explorer runs the whole pipeline end to end. We'll be re-running this study in six months, when the agent era is eighteen months deep instead of twelve, and I'm genuinely curious whether the protective gap widens, holds, or closes. Either way, we'll show the numbers.